

まえがき
こんにちは。デジタルテクノロジー統括部アナリティクスグループ新卒の安藤です。前の記事から3ヶ月も空いてしまいました......。
先日9/19-23に行われた国際学会RecSys 2022をオンラインで聴講したので、その報告として記事を書くことにしました。パーソルキャリアからは私を含め3名以上が参加したと聞いています。
The ACM Conference on Recommender Systems、通称RecSysは推薦システムに関するトップカンファレンスであり、ジョブマッチとは密接な関わりがある分野です。
推薦システムの最先端がどのようなものであるかを知ることでビジネスに活かしたいとの思いから参加を申し出た、という経緯です。
(かなり直前の申請でしたが許可をいただくことが出来ました。この場を借りて改めてお礼申し上げます......!)
非常に興味深い発表が多数ありましたが、最も面白いと感じた発表の中からHR領域で2つ、オフ方針評価の領域で1つ取り上げて簡単にご紹介します。
興味のあるものがあればぜひ当該論文もしくはプレゼンテーションをご覧ください。
また、各項目で紹介する図や数式は全て当該論文もしくはプレゼンテーションからの引用となります。
- まえがき
- 発表紹介
- 全体を通しての所感
- おわりに
- 参考文献
発表紹介
Modeling Two-Way Selection Preference for Person-Job Fit [Yang et al., 2022]
(求人-求職者のフィッティングのための双方向の選好性のモデリング)
【一文サマリー】
求人と求職者の双方向的な選好のグラフ表現とBERTでエンべディングした職務経歴書を用いて、「求人→求職者」と「求職者→求人」の選好スコアを個別に算出する手法を開発した。
【前提】
世の中には多数の推薦システムが存在しますが、求職者と求人のマッチングは通常の推薦と異なり、「求職者→求人」と「求人→求職者」の両方にとって満足度が高いものであることが望ましいと言えます。
この発表は、そのような相互の(Reciprocal)推薦モデルをグラフ表現学習によるリンク予測として実施した研究です。
なお本発表と直接は関係ありませんが、RecSys 2022では知識グラフを利用したチュートリアル[Balloccu et al., 2022]が行われており、近年活発な研究分野であることが伺えます。
本発表のモデルの全体像は以下の図のようになっています。
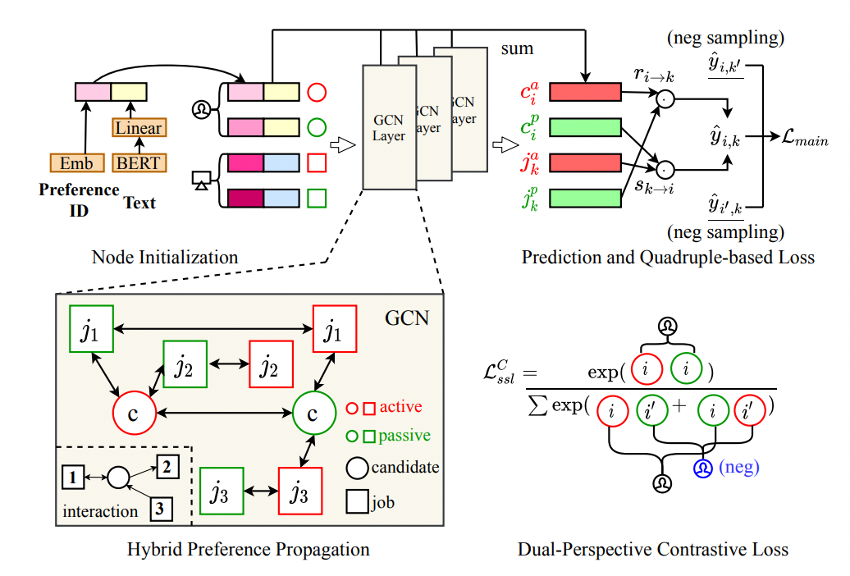
【双方向のインタラクショングラフ表現】(図の左下)
まず、求職者と求人の関係をグラフとして取得します。
求職者と求人はそれぞれactiveとpassiveという2つのノードを持ちます。
ここで、
- 求職者activeと求人passiveとの間のエッジは求職者から求人への応募があったこと
- 求人activeと求職者passiveとの間のエッジは求人が求職者にアプローチしたこと
を示します。
両者が合意に至った場合、①と②の両方でエッジが存在することになります。
【ノード表現の初期化】(図の左上)
各IDをエンべディングしたものと職務経歴書のテキスト
をBERTを用いてエンコードしたエンべディングを組み合わせたものを初期値
として各ノードに付与します。すなわち、
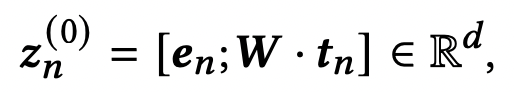
です。
【GCNによるグラフ畳み込みとそれによる予測】(図の中央上・右上)
グラフとノード表現の初期値を得ることが出来たので、Graph Convolutional Networksを用いてグラフ構造の畳み込みを行います。
論文ではlightweight propagation mechanismという手法を用いて中間層の表現を得ているようです(私があまりこの分野に詳しくなく……すみません)。
最後に、この手法で得た初期値と中間層の値の平均を取ることで各ノードの最終的な表現値を得ます。
こうして得られた表現値から求職者→求人、求人→求職者の選好に関するスコアを得ることが出来るので、その平均を選好の予測値とします。
【双方向のランキング最適化】(図の右下)
ジョブマッチにおける双方向性を持つ損失関数として、著者はBayesian Personalized Ranking(BPR)を双方向的に拡張したものを提案しています。
通常のBPRでは、ある求職者が求人
への選好を示した時、選好を示さなかった他の求人
よりも選好スコアの値が大きくなるようにパラメータのMAP推定をすることを考えます(すなわち、
>
)。
本発表では >
のみならず
>
をも考慮し、全ての組み合わせに対して次のような損失関数を算出します。
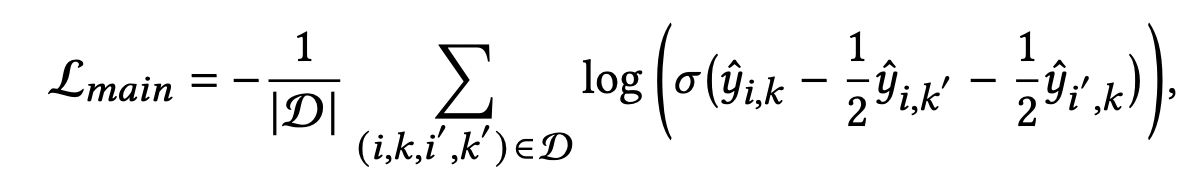
さらに、同じ求職者のactiveノードとpassiveノードの類似度は高く、別の求職者のノードとの類似度は低いほうが良いと考えます。
そこで、
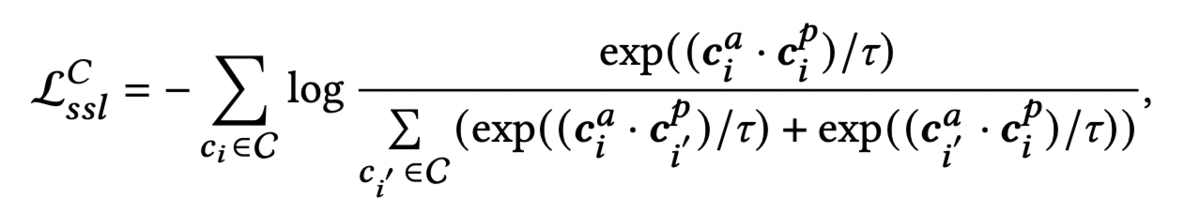
を損失関数に加えます。
求人についても同様にを考え、
とします。
ここで最終的な損失関数は
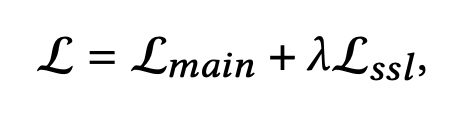
となり(はハイパーパラメータ)、これを最小化することで最終的なパラメータが求まります。実験結果は当該論文をご覧ください。
【ユースケース】
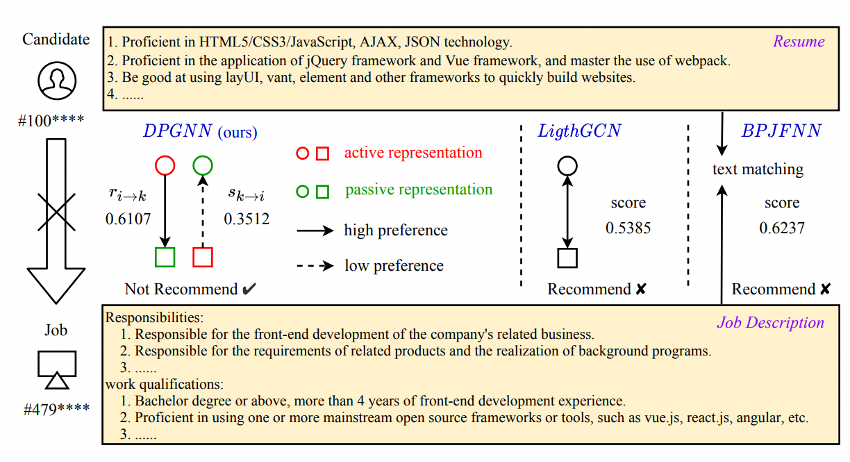
発表で示されていたユースケースのスライドです。
求職者側の職務経歴書と求人側の採用条件がテキストとして示されており、DPGNN(本研究の手法)とLightGCN・BPJFNNを比較した結果が示されています。
興味深いことに、LightGCN・BPJFNNでは高いスコアが出ているので推薦するという結果となっていますが、DPGNNでは求人側から求職者への選好スコアが低いため推薦していません。
DPGNNでは、このケースのように両者の選好スコアが異なる場合には特に有効である可能性があります。
【感想】
求人側・求職者側両方の選好スコアを求める研究はいくつかありますが、両者の双方向的な興味の有無に焦点を当てている点で非常に興味深く、スケールするのであれば弊社のプロダクトでも何かしら使えたらいいなと思っています。
また、案件を取りまとめ求職者様と企業様をつなぐ人材紹介サービスにとっても、両方のスコアがわかることでより質の高いご案内が出来るようになるかもしれません。
Reciprocalな推薦は今後人材業界AIでは必須になってくるでしょうから、どんどんキャッチアップしていきたいです。
Model Threshold Optimization for Segmented Job-Jobseeker Recommendation System [Jin et al., 2022]
(求人-求職者推薦システムのセグメントごとのモデル閾値最適化)
【一文サマリー】
求人マッチのようにセグメントごとにモデルのパフォーマンスが異なる場合、別々のモデルを構築したりオンラインでの強化学習アプローチを取るよりも、オフラインでモデルの閾値を決定することで望ましい形で推薦の質と量をともに向上させることが出来る。
【概要】
多くの求人推薦システムが求職者や求人側の反応を予測するモデルを持っていますが、業種・職種などのセグメントが異なるとパフォーマンスも大きく異なることがあります。
異なるセグメントごとに異なる特徴量を追加したり別のモデルを開発したりすることでそのギャップを埋めることも可能です。
しかし、筆者らはindeedでの3つの実例の結果を示し、セグメントごとにオフライン学習を用いて最良の閾値を設定するのが最も実用的かつ効率的な方法であったと主張しています。
例えば、以下のような3つのモデルのチェーンを想定します。
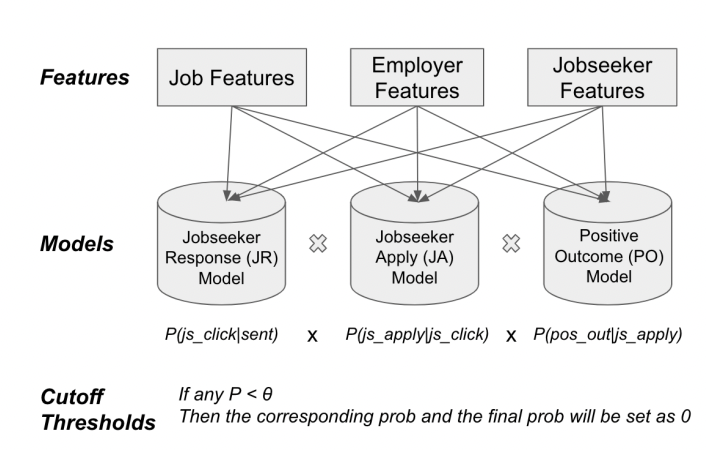
求人推薦を送った時にマッチングが成立する確率を次の3つの確率の乗算で表します。
- 推薦を送った時に求職者がクリックする確率
(Jobseeker Resoponse Model、 JRモデル)
- 求職者がクリックした時に応募する確率
(Jobseeker Apply Model、JAモデル)
- 応募があった時に企業が内定を出す確率
(Positive Outcome Model、POモデル)
ただし、モデルごとにカットオフ値を設定し、一定値を下回る場合に0とします。
このようにカットオフ値を設定することでprecision(適合率、陽性適中率)は高まりますが、recall(再現率、感度)は減少します(推薦を送る対象を絞ると取りこぼしも増えるため)。
【最初の試み:セグメントごとに異なるモデルを開発】
チームは最初の試みとして、いくつかのパフォーマンスが低いセグメントに対して専用のモデルを開発しました。
ここでは求職者からの応募数や応募に対するポシティブなアクション数は上昇したものの、それぞれの確率は下降しており、推薦の量と質の両方を上昇することが出来なかったと報告しています。
また、このモデルではモデルの改善のために新たな特徴量の追加や異なるエンべディングの追加などを継続的に行っていましたが、大規模なモデルでのパラメータのファインチューニングによる更新は初期のエンジニアリングコストとインフラの維持という両面で高価であり、次第に一貫性のないものになっていきました。
【二番目の試み:多腕バンディットによるオンライン強化学習】
以前の実験を踏まえ、Indeedのチームは次のように前提を整理しました。
- 推薦の量(推薦への応募数
と応募へのポジティブなアクション数
)と質(推薦への応募率
と応募へのポジティブなアクション率
)の全てを同時に改善したい
- モデルのパフォーマンスに応じてそのうちどれを重視するかを変えたいこと
- さらにサービス品質(Service Level Agreements, SLO)の担保として、購読解除やネガティブなフィードバックの確率を一定値以下にしたい
これらを解く最適化問題は次のようになります。
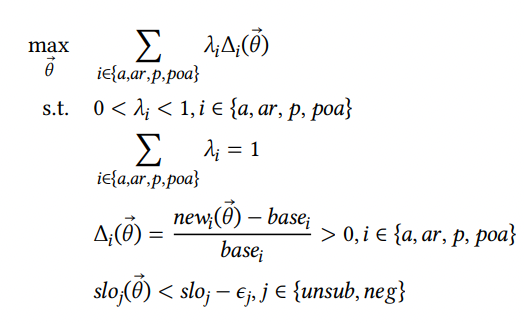
ここでは各指標に対する重み、
は
のもとでの各指標の上昇値を、
はハードマージンである
に対するバッファを指します。
最適化する変数はセグメントごとのモデルのカットオフ値です。Indeedチームはこれを多腕バンディット問題としてオンライン学習の中で解こうとしました。
しかし、閾値が異なるグループでの比較に確実性・一貫性がないこと、サンプルサイズが小さいセグメントでは収束するのに長い時間がかかること、応募に対する雇用者側の反応を取得するのに数週間かかるために起きるデータ遅延の問題などから、この手法も実用的ではないとチームは結論づけました。
【三番目の試み:オフラインでのセグメントごとに閾値チューニング】
推薦の質と量をともに向上させるためにはセグメントごとの閾値の調整が必要であるものの、オンラインでの強化学習アプローチが実用的ではないと結論づけたチームは、貪欲法を用いたオフライン評価で閾値を決定することを決めました。
このケースでは
- 応募率はJAモデルの閾値と相関し、企業からのポジティブアクション率はPOモデルの閾値と相関していた
- 応募数はJAモデルの閾値を上げると下がるか横ばいであり、企業からのポジティブアクション数はPOモデルの閾値を上げると下がるか横ばいであった
- JRモデルとこれらの指標には明確な関係が得られなかった
ことから、JAモデルとPOモデルの閾値と4つの指標の加重平均(これをとします)との間にはについては上図のような関係が見られます。
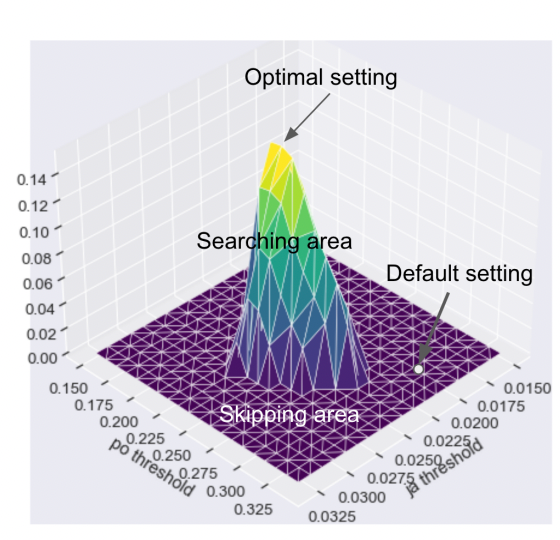
つまり、例えば一度応募数がデフォルトより下がらない・ポジティブなアクション率がデフォルトより下がらない閾値の範囲を決定し、その中で加重平均が最大になる点を探索するといった方針を取ることが出来ます。
さらに、これを全てのJOモデルの閾値に対してフルグリッドサーチを行うことで、3つのモデルに対して最適な閾値を求めることが出来る、という考え方です。
実験結果についてはこれまた当該論文をご参照いただきたいのですが、小売店のセグメントでは応募数・ポジティブなアクション数を2倍弱にしつつ応募率・ポジティブなアクション率をも向上させることに成功したようです。
このように、推薦量の向上をメインにしつつ推薦の質の向上も担保する、といったことが出来るのがこの手法の強みであると言えます。
【感想】
技術的にものすごく高度なことをやっているという印象はありませんでしたが、複数モデルを開発すると維持コストが高くなるという問題にまさに今直面していたところなので、すごく役に立つ話を聞くことが出来たと思って聞いていました。
たまたま筆者らの事例でうまくいっただけなのでは、と思わないでもないですが、個別にモデルを作り始める前にオフラインで出来ることがたくさんある、それでどうしようもなければ個別にモデルをつくるという順序でやるのがよいのでしょう(当たり前かもしれませんが)。
Improving Accuracy of Off-Policy Evaluation via Policy Adaptive Estimator Selection [Udagawa, 2022]
(ポリシー適応的推定量選択によるオフ方策評価の精度の向上)
【一文サマリー】
オフ方策評価で真の損失関数の良い近似を得るためには推定量の適切な選択が必要なので、手元のログデータを適切にサンプリングして推定量を決定する手法を開発した。
【前提】
推薦システムに限りませんが、機械学習モデルによって得られる何らかの予測値は「推薦をする/しない」という判断とイコールではありません。
純粋な予測値を得たい、というケース以外では本来我々が良し悪しを判断したいのは意思決定方針であると言えるでしょう。
最も良いのは実際にA/Bテストで新しい意思決定方策と古い意思決定方策を決めることですが、A/Bテストにはコストがかかります。
そこで、すでに手元にあるデータを使って機械学習モデルを使った方針を評価することを考えます。
しかし、ナイーブに算出した経験損失の期待値と真の損失関数との間にはバイアスが存在することが知られており、真の損失関数の良い近似を得るためにInverse Propensity Score(IPS)推定量やDoubly Robust(DR)推定量、さらにそれらを改善したものが提案されています。
(こうした分野については『施策デザインのための機械学習入門』[齋藤, 2021]やCONSEQUENCESワークショップ内のチュートリアル[Saito, 2022]にまとめられているので、ぜひそちらもご覧ください。これらの文脈を押さえないとやや理解が難しいかもしれません)
前述の通り様々な推定量が提案されているのですが、どの推定量が良いかはデータサイズや意思決定方策のパターン数、ノイズなどのために個別のケースによって異なります。
そのため、可能な限り真の損失関数に関して最も良い近似であると考えられる推定量を選びたいと考えます。
【モチベーション】
ユーザーの情報を、ユーザーの情報を得た時の意思決定方針
、得られる報酬を
、これらをまとめたデータ
を
とします。
ここで、はデータの収集方針でもあることに注意してください。
また、新たな方針に従って得られる真の報酬を
、データから計算できる報酬の期待値を
とします。
オフ方策評価では、を
の近似であると見なします。
ここで平均二乗損失は次のようにバイアスとバリアンスに分解可能です。
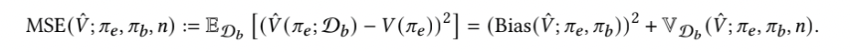
![]()
一般に、バイアスとバリアンスはトレードオフの関係にありますが、当然ながらバイアスとバリアンスはデータによって異なります。
そのため、どのような推定量が良いかはデータに依存します。
そこで、適切な手法でからサブサンプリングを行い、そこで得られたサブログデータ
とサブ評価データ
における最適な推定量を選ぶことが出来れば、今後のデータ
でも平均二乗損失
を最小化出来る可能性が高いと考えます。
【Policy-Adaptive Estimator Selection via Importance Fitting (PAS-IF)のコンセプト】
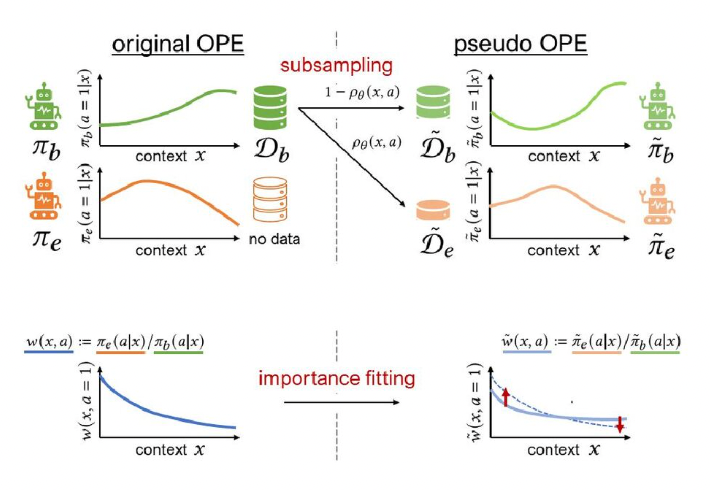
さて、「適切なサブサンプリング」とはどのようなものでしょうか。
IPS推定量、DR推定量およびその発展型の多くが報酬を重み付けする重要度を用いて
を得ています。
従って、サンプリングパラメータに従って得られた(ブートストラップ)サブログデータを使って得られる重要度
と全ログデータを使って得られる重要度
との間の距離が小さければ、サブログデータ
とサブ評価データ
の平均二乗損失を最小化する推定量が
でも最適な推定量である可能性が高いと言えます。
PAS-IFでは、勾配降下法によってと
間の距離を最小にする
を求めることで最適な推定量を定めています。
の計算方法や
と
間の距離を最小化する方法、実験結果等については当該論文をご参照ください。
【感想】
オフ方策評価についてはいろいろな推定量が出てきてどれを使えばいいのか......と思っていたので、データ内で擬似A/Bテストを行って推定量を選ぶという考え方は面白いなと感じました。
そもそも予測値と意思決定方針の評価は同じではないということ自体の認識が社内でまだ一般的ではないかとも思うので、もっと普及していければと思っています。
全体を通しての所感
現代の推薦システムは他分野で発展してきた人工知能に関する技術の応用の場であり、自然言語処理・強化学習・グラフ理論・オフライン/オンライン学習など関連技術は非常に多岐にわたります。
研究の最先端がどこにあるのか、どんなトピックがあるのかを知り自社のビジネスに取り入れていくのに非常に役立つ場であったように思います。
学生時代の専攻が情報科学ではなかったということもあり自分自身の知識不足を実感する部分も多かったのですが、世界中の研究者や企業の方々が「どうすればより良い推薦を行うことが出来るか?」と考え様々な手法を考案・応用しているのを見たことでモチベーションとインスピレーションを大きく掻き立てられました。
本会議だけでなくワークショップやチュートリアルで得られる知識も多く、もし参加される方がいれば是非そちらにも参加することをおすすめします。
こうしたところで培った技術を実践し、顧客の皆様に役立てるようにしていきたいと思います。
発表を読み解く力も実装力ももっともっとつけていきたいです......!
おわりに
「時差がしんどい」「英語がわからない」など色々大変なところはありましたが、とても勉強になるエキサイティングな1週間でした。
末筆ではありますが、本学会への参加にあたって快く許可してくださったマネージャー、時差対応に応じてくれたチームの皆様に心より感謝申し上げます。
本シリーズの前2回の記事はこちらです。今見るとちょっと恥ずかしい。
新卒データサイエンティストの成長ストーリー #1 AWSでWordPressサイト構築に挑戦 - techtekt
新卒データサイエンティストの成長ストーリー #2 クエリを書く、その前にテーブルを見る - techtekt
参考文献
Yang, C., Hou, Y., Song, Y., Zhang, T., Wen, J.-R., & Zhao, W. X. (2022). Modeling Two-Way Selection Preference for Person-Job Fit. Sixteenth ACM Conference on Recommender Systems, 22, 102–112.
Balloccu, G., Boratto, L., Fenu, G., & Marras, M. (2022). Hands on Explainable Recommender Systems with Knowledge Graphs. Sixteenth ACM Conference on Recommender Systems, 710–713.
Jin, Y., Alampally, A., Toshniwal, D., Xu, Z., & Girdhar, A. (2022). Model Threshold Optimization for Segmented Job-Jobseeker Recommendation System. Sixteenth ACM Conference on Recommender Systems.
Udagawa, T., Kiyohara, H., Narita, Y., & Tateno, K. (2022). Improving Accuracy of Off-Policy Evaluation via Policy Adaptive Estimator Selection. Sixteenth ACM Conference on Recommender Systems.
齋藤 優太, 安井 翔太, 株式会社ホクソエム 監修 (2021). 施策デザインのための機械学習入門〜データ分析技術のビジネス活用における正しい考え方. 技術評論社.
Saito, Y. (2022). RecSys2022 Workshop Tutorial Approaches to Off-Policy Evaluation in Large Action Spaces. Retrieved October 8, 2022, from https://drive.google.com/file/d/1ORptVOsM6zDImhRhJsoTpMdKiAhu2I7x/view

安藤 有瑠聡 Aruto Ando
デジタルテクノロジー統括部 デジタルビジネス部 アナリティクスグループ
2022年度新卒入社。学生時代は看護系の学科で看護師のエキスパートシステムの開発やベイズモデリングによる創傷の予測に関する研究を実施。9月より人事制度に関するデータ分析や社内AIプロジェクトに参加。社内のあらゆる人々がデータドリブンな意思決定を出来るような支援をしていきたいです。最近の休みは大体FF14をしています。
※2022年10月現在の情報です。
パーソルキャリアでは、「人々に『はたらく』を自分のものにする力を」というミッションを実現したいエンジニア・データサイエンティストを募集しております。
ご興味がありましたらぜひ以下のリンクをご覧ください!