

はじめまして!デジタルテクノロジー統括部アナリティクスグループ2022年度新卒の安藤と申します。
同期の倉持さんが完璧な導入をしてくださっていますが、このシリーズではデジタルテクノロジー統括部の新卒一年目がどのようなことを学んでいるか、また一年目をどのように過ごしているかというところに焦点を当てています。
今のところ倉持さんと私で交互に書いていく予定です(どうなるかわかりませんが......)。
今回は『自己紹介』『クエリを書く、その前にテーブルを見る』『配属一ヵ月の新卒から見たデジタルテクノロジー統括部の印象』と、3つの章に分けてお送りします。
この記事は以下のような方におすすめです!
- 非理工系・非情報系からのデータサイエンティストへの就職に興味がある方
- パーソルキャリアの新卒1年目のデータサイエンティストに興味がある方
- 新卒データサイエンティストへの研修を考えている方
- データベースやSQLに触り始めたくらいの人
自己紹介
研究の紹介
看護系の大学院で褥瘡(じょくそう、寝たきりの方などで圧迫が持続的に加わることによって起きる傷)の研究をしていました。研究テーマは「熟練看護師のケアアルゴリズムの開発」「褥瘡重症度スコアの予測分布推定」で、看護師へのインタビューの解析や予測モデルの構築などをやっていました。
研修開始時点でのデータサイエンスの実力
- プログラミング
RとPythonがある程度書ける、Juliaはかじった程度でした。
大学院では主にRをベースにで前処理を行い、必要に応じてStanでモデルを書いたりscikit-learnなどのライブラリを使ったりしていました。
- 統計学・機械学習
「機械学習プロフェッショナルシリーズ(講談社)」で言うと、「スタートアップシリーズ(緑色のシリーズ)」なら頑張ればなんとか読める程度でした。
現在統計検定準一級の合格を目指しています!
- その他
ネットワークやデータベース、/Linuxなどについてはほぼ無知と言ってよい状況でした。倉持さんと同じくクラウドコンピューティングの知識もなく、ざっくり言って精進中というところです。
クエリを書く、その前にテーブルを見る
概要
新卒に与えられた研修の一つに、SQLを用いたデータハンドリング技術の習得というものがありました。そんなわけでガンガンクエリを書いているのですが、悪戦苦闘するうちにSQLのクエリを書く前にいろいろすべきことがあるのでは?と気づきました。
今回は初心者目線で感じた「クエリを書く前に気を付けるべきテーブルの見方」をお伝えできればと思っています。
SQL研修の目的
データを活用したビジネス運営をより進めていくために、データサイエンティストとして正しくデータを取り扱う技術を習得する事(たぶん)
SQL研修の背景
デジタルテクノロジー統括部はビジネス、エンジニアリング、アナリティクスと3つのグループに分かれていますが、どのグループであってもSQLでデータベースに対してアプローチできる能力が必要とされます。
機械学習モデルの構築にせよデータ可視化にせよ、まずはデータを取り出すところからスタートです。私達の業務上必須のスキルになっています。
学生時代RやPythonのモダンなパッケージを使って甘えた前処理をしていた私のような人間からするとSQLを通したデータベース操作は正直難しいのですが、これを習得しないと始まらないのです。
この研修は
- ProgateでSQLの初歩を学習
- 先輩社員から出された問題集を解いていく
という流れで進行しています。
Progate研修を終えたところで私は「SQLこんなもんか~楽勝だな~」と思っていたのですが、問題集を解き始めたところで私は自分の認識の甘さを実感し始めました。
企業のデータベースは非常に巨大で複雑でしばしばちょっぴりレガシーなので、テーブル構造や変数の意味を理解することが重要です。今回は研修用に先輩方がそういった環境を用意してくださったので、実務に近い状態を知ることができました。
そのため、いきなりクエリを書く前に「テーブルを見る」という過程が発生します。
以下はその問題集を解きながら感じた「クエリを書く前に気を付けるべきテーブルの見方」です。
漫然とテーブルを見ていても何も頭に入ってこない!という方は気を付けてみてみるとよいかもしれません。
テーブルを見るときのポイント
- 仕様書をよく読む、わからなくなったら仕様書に戻る
言うまでもなく重要な仕様書ですが、「はあはあ」「へえへえ」と読み流していると誤解したまま抽出過程に進んで時間を大幅にロスする、ということが起こりえます。「なんだかよくわからん!」となった時には仕様書に戻ることが非常に重要だと感じます。
- レコードを一意に定めることが出来る主キーは何か、主キーは単一なのか複合キーなのか
これもとても大事ですね!
「このテーブルにはこの主キーによって一意に定まるレコードが入っている」ということを意識するとテーブルの見通しが良くなります。
ただし、時系列を扱うようなデータは要注意です。
最新のデータだけを保存しているテーブルAと、それまでの履歴が全て保持されたテーブルBを比較する場合を考えます。
テーブルBでは、テーブルAの主キーに加えて時系列を示す何らかの属性がなければレコードを特定できませんね。
社員の作業進捗を管理するようなデータベースを考えてみます。
山田さん、鈴木さん、佐藤さんの3人がおり、作業がA→B→C→Dの段階で進むとします。それぞれの社員は作業が終わった日を記録する、というシステムです。
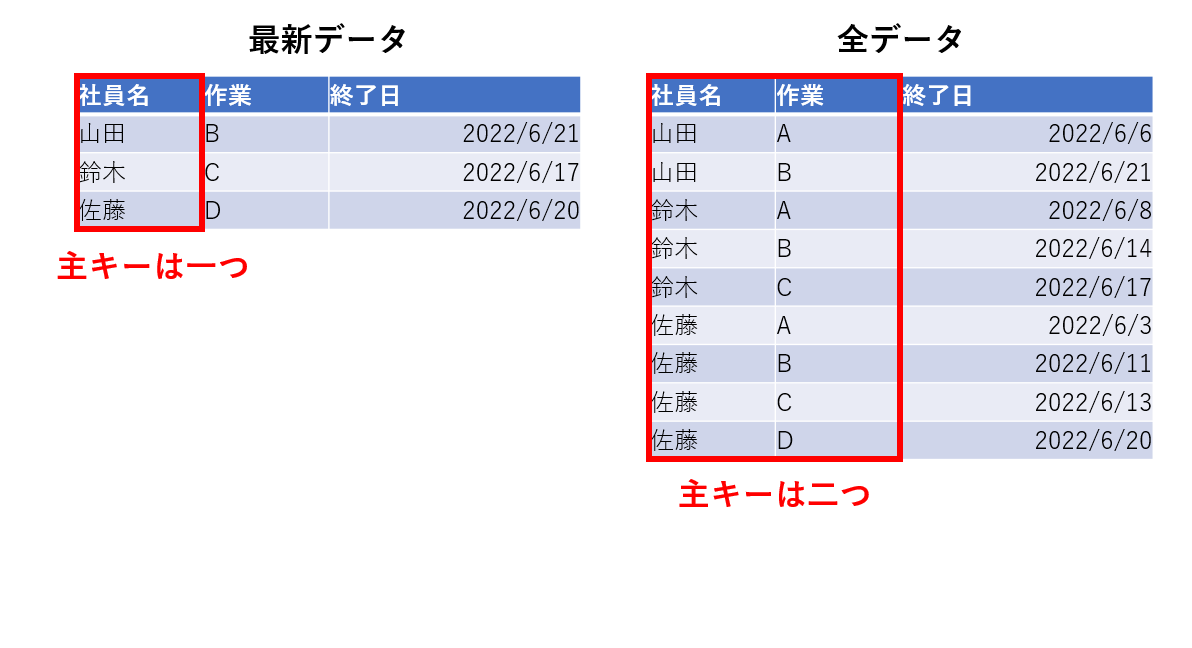
最新データのみが保存されたテーブルの主キーは"社員名"だけですが、全データが保存されたテーブルの主キーは"社員名"と"作業"の複合キーです。
当たり前だと感じるかもしれませんが、テーブルが複雑になってくると混乱してくるので意識するとよいかもしれません。
- 単位は何か
例えば金額なら千円単位、一万円単位、百万円単位などがあり得ます。これらを比較する際は単位に気を付けましょう。
- NULLを許容しない属性はどれか
逆に言えばNULLを許容する属性にはかなり高い確率でNULLが入っています。信じられるのはNOT NULL制約がつけられたカラムだけ……。
- データが第2正規化されていない場合は属性の従属関係を把握する
→実務上は第2正規化されていないテーブル、すなわち複合主キーのうちどれか一部に従属するような属性があるテーブルを扱うこともあると思います。
例えばECサイトのデータベースの中の販売に関するテーブルを想像してみます。”会員ID”と”商品ID”の二つによって一意にレコードが定まるようなテーブルの中に、”会員ID”だけで確定する”入会日“などの属性が入っているパターンですね。
先ほど例に出した時系列データなどでもありがちです。
適当に進めているとそのうちどれがどれに従属しているんだっけ?ということがわからなくなり、全てが崩壊します。最初に把握しましょう!
配属一ヵ月の新卒から見たデジタルテクノロジー統括部の印象
このようなSQLやデータベースまわりの研修を含め、さまざまなことを学びながら配属後の一ヵ月を過ごしていました。一方で先輩社員や上司の皆さんと接する中で「デジタルテクノロジー統括部」という組織がどういうところなのかというのも少しずつ見えてきました。
一言で言うと「矜持と自主性」だと感じました。デジタルテクノロジー統括部は「人々に、“はたらく”を自分のものにする力を」というパーソルキャリアのミッションを、データとテクノロジーから実現することを目的とした組織であり、先輩の皆さんが会社の中でも新たな部分を切り開いていくという矜持をもって働いているのを感じます。
自主性が重要視される傾向があり、仕事は自分から他の部署を巻き込んで作り出していくという文化が強いです。中途入社の方が圧倒的に多い部署なので、良い意味で異端な人が多いようにも感じます。個人的にはとても居心地がよいので、自分もいい仕事が出来るよう精進していくぞ、という所存です。
今後も定期的に研修やOJTの様子について発信していきますので、次回の記事も是非ともご覧いただければと思います。何卒!

安藤 有瑠聡 Aruto Ando
デジタルテクノロジー統括部 デジタルビジネス部 アナリティクスグループ
※2022年7月現在の情報です。