
こんにちは。デジタルテクノロジー統括部でアナリストをしているY・Nです。
パーソルキャリアでは日々、dodaに登録された転職希望者に対してキャリアアドバイザー(以下CA)がキャリアに関するカウンセリングを行っています。そこでは今までのキャリアの棚卸しから今後のキャリアプラン、その上で転職希望ならば転職理由や次の職場に求める希望などのたくさんの言葉のやり取りを経て、登録者に合った求人をCAが提案しています。
このCAが一人一人に合った求人を提案するサービスですが、CAの仕事量に限りがある、ノウハウが属人化していてどのCAが担当になるかによって提案内容に差がある、等の問題があり、求人の提案をAIによって代行あるいは補助させることにより、もっと多くの方にもっと良質な提案が出来ないか検討されてきました。
これまでの検討では、転職希望者の職務経歴やスキル、業種や職種や年収などの項目をデータベースに入力し、ルールベース或いは機械学習モデルで登録者と求人のマッチ度合いを予測させていましたが、予測内容を検証してみるとCAの提案に比べて"合っている"と感じる率が低い状態でした。
それも当然の話でして、コンピュータは上記の様な(業種、職種、年収など)はっきりと数値化やカテゴリ化出来る要素のみを用いて予測していましたが、CAはそれらに加えてカウンセリング中の言葉から、性格や志向性、ソフトスキル等数値化やカテゴリ化がしにくい要素をも加味して提案を行っているからです。
このはっきりと数値化やカテゴリ化しにくい要素を取り扱うことはこれまでコンピュータが苦手としていましたが、昨今のディープラーニングによる自然言語処理手法の発達により、言葉の意味をコンピュータでもかなりうまく取り扱えるようになってきました。そこでデジタルテクノロジー統括部では、(事前に同意を得た)転職希望者とCAのカウンセリング会話をテキスト化した上で処理し、カウンセリング中の言葉からさまざまなことを判断する、というこれまでCAが独占的に持っていた能力をコンピュータにも備え付けさせた上でサービス向上に役立てる、というプロジェクトを進めています。
本記事ではその中の自然言語処理モデルの骨子の部分を説明します。
[tex:]
モデル骨子
テキストから得られた情報をマッチングの特徴量にする、希望者の性格や志向性を分類する、CAのカウンセリングの振り返りや教育に活用する、等々の様々なタスクがありますが、骨子となる部分はほとんど共通しています。BERT(ALBERT/RoBERTa)の日本語学習済みモデルを利用し、テキストの分散表現を得ることから始めます。
ですが、BERTは文章をトークンに分けたときにトークンの数が512個までの文章しか対応していないので、トークンが512個以上になる約90分のカウンセリングにそのまま適応させることは出来ません。

そこで、各発話毎にBERTを適用して
\begin{align}
1文目:s_1&\overset{\tiny{BERT}}{\rightarrow}[CLS]_1 \\
2文目:s_2&\rightarrow[CLS]_2 \\
&\vdots \\
i文目:s_i&\rightarrow[CLS]_i\\
&\vdots \\
l文目:s_l&\rightarrow[CLS]_l
\end{align}
という様に各発話のベクトルを抜き出し、得られたベクトルに対して更にBERTと同じ様なSelf Attention機構に入れることによってカウンセリング全体の意味を取得します。
\begin{equation}
\text{Attention}([CLS]_0,[CLS]_1,[CLS]_2\dots,[CLS]_i,\dots,[CLS]_l)
\end{equation}
ここではBERTで文頭につける
に対応しています。
同じ様なことが以前よりLSTMで行われていましたが(各文をLSTMでベクトル化し、得られたベクトルを再度LSTMに書けることによって文章全体の意味を取り出す)、それのAttention版の様なイメージです。
モデルの概要を図に表すと以下のようになります。
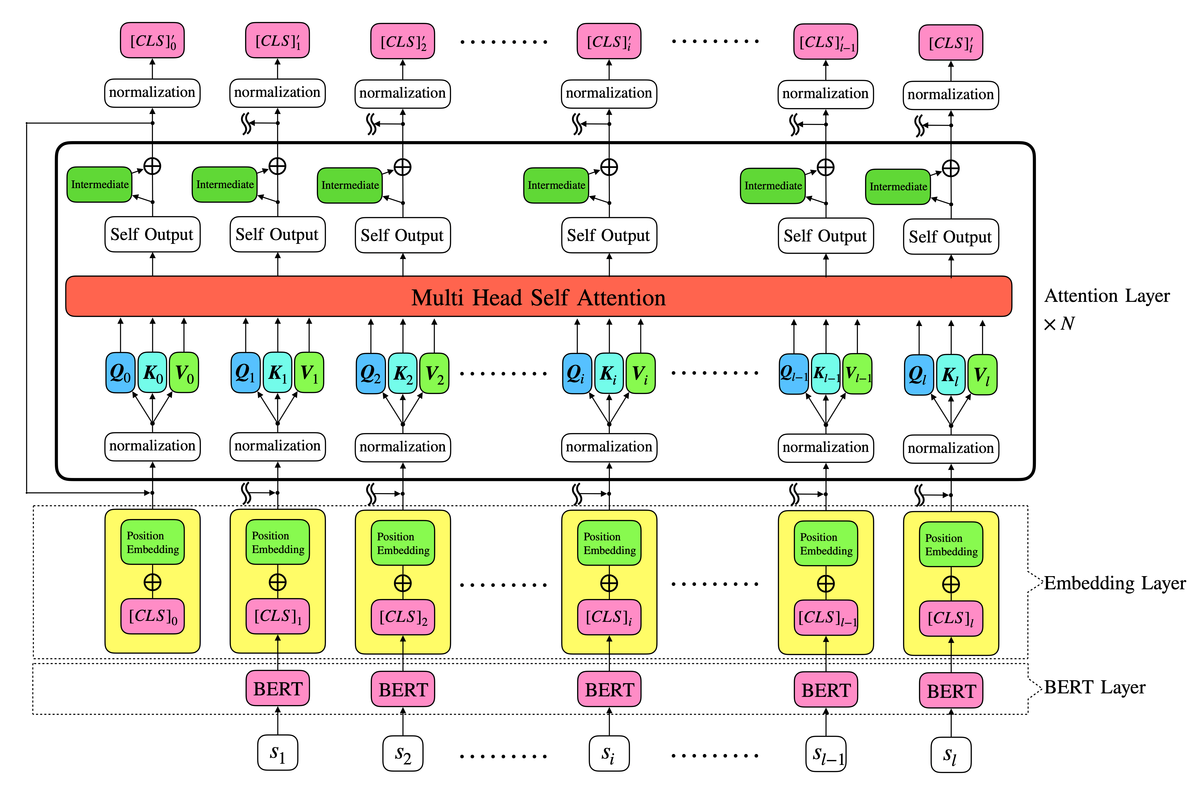
まずBERTLayerで各から
の768次元(BERT及びRoBERTaの場合、ALBERTの場合は128次元)ベクトルを取り出します。
次にEmbedding Layerですが、BERTでは
となっていました。ここでToken Embeddingsは分割されたトークンを分散表現で表しますが、ここでは既にを出した時点で得られています。Segment Embeddingsは入力された文章が1文目か2文目かを表すものですが、今回は単一のカウンセリングを扱うので使いません。そしてトークンの順番(今回の場合は発話文の順番)を表すPosition Embeddingsを足し合わせて、Attention Layerに入力するベクトルは
となります。
Position Embeddingsに関してですが、TransformerのようにPositional Encoderモジュールを用いて、順番が番目のトークンのPosition Embeddingsを
という様に関数で決めてしまうパターンと(Sukhbaatar, Szlam, Weston, Fergus, 2015)、BERTのように全て学習させるパターンの両方を試してみて、良い方を採用します。
Embedding Layerの次はMulti Head Attention Layerです。まずNormalizationユニットで各の768個の特徴量を、平均が0、標準偏差が1になるように正規化します。(正規化したものを
とします)
その後、より柔軟性と表現力をもたせるためにQueryとKeyとValueに分離します。各に対して学習させる行列
をかけて
\begin{align}Q_i = W^qa_i \\ K_i = W^ka_i \\V_i = W^va_i\end{align}
とし、Dot-Product Attentionを取ります。
\begin{align}Attention_{i}=\sum_{j=0}^nsoftmax\left(\frac{Q_i\cdot K_j^{\mathsf{T}}}{\sqrt{dim}}\right)V_j\end{align}
この様にして学習させることによって、互いに互いを(自明には)予測できない程の別物に分離させる事ができます。(Miller, Fisch, Dodge, Karimi, Bordes, Weston, 2016)
これで1つのAttentionが出来ましたが、性能向上のためBERTと同じようにこれをMulti-Head化します。AttentionのHeadをと番号をつけていくと、
番目のHeadのAttentionは
\begin{align}Q_i^p = W^{p,q}a_i^p \\ K_i^p = W^{p,k}a_i^p \\V_i^p = W^{p,v}a_i^p\end{align}
\begin{align}Attention_i^p=\sum_{j=0}^nsoftmax\left(\frac{Q_i^p\cdot {K_j^p}^{\mathsf{T}}}{\sqrt{dim/h}}\right)V_j^p\end{align}
となり、番目の発話
のAttentionが以下のようになります。
\begin{align}Attention_{i}={\mathrm{concat}}\left(Attention_{i}^1,\dots,Attention_i^p,\dots,Attention_i^h\right)\end{align}
得られたAttentionを入力サイズと同じ出力サイズで全結合、正規化、ドロップアウトしてSelf Outputとします。このSelf Outputに対して、適当な中間サイズ(BERTの場合は3072)で全結合し、適当な活性化関数(BERTの場合はGELU)をかけたものをIntermediateとして、Self OutputとIntermediateを足し合わせたものを最終的なAttention Layerの出力とし、これを回繰り返します。
そうして出力された各が、
番目の発話の重み付けられた意味となり、一番最初の
がカウンセリング全体の意味としてベクトルで表現されることになります。
ここまでで基礎モデルが完成したので、後はBERTから各種タスクに転移学習するのと同じ要領で、各の上に層を積み重ねる形でいろいろなタスクに転用していきます。
ここで、教師あり学習ならば上記の通り各の上に各タスクの層を積み重ねて、教師との損失関数を逆伝播させればよいのですが、中には教師データを十分あるいは全く集められないタスクも発生します。その様な場合でもうまく学習やクラスタリング等が出来るように、ここでもBERTの事前タスクMasked Language Modelと同じ様な手法を使って事前学習させます。Masked Language Modelは、
入力テキスト
[はじめまして、パーソルキャリア株式会社の峯尾と申します。本日はどうぞよろしくお願いいたします。]
を入力した際に、文をトークンに分割し、
['[CLS]','はじめ', '##まし', '##て', '、', 'パーソ', '##ル', '##キャ', '##リア', '株式会社', 'の', '峯', '尾', 'と', '申し', 'ます', '。', '本', '##日', 'は', 'どう', '##ぞ', 'よろ', '##しく', 'お願い', 'いた', '##し', 'ます', '。', '[SEP]']
分割したトークンの一部を[MASK]に置き換え
['[CLS]','はじめ', '##まし', '##て', '、', 'パーソ', '##ル', '##キャ', '##リア', '[MASK]', 'の', '峯', '尾', 'と', '申し', 'ます', '。', '本', '##日', 'は', 'どう', '##ぞ', 'よろ', '##しく', '[MASK]', 'いた', '##し', 'ます', '。', '[SEP]']
ここで、
[MASK](1つ目)→株式会社
[MASK](2つ目)→お願い
という様に置き換えた[MASK]を当てていくタスクです。各トークンはID化されているので、ID数の多クラス分類となり、クロスエントロピーを損失関数として逆伝播させていました、
今回の場合
とした際に
がID化されていないため多クラス分類で求めることは出来ないので、最終出力の
と
の距離(コサイン類似度など)を損失関数に設定します。
\begin{align}E=distance\left([CLS]_3,[CLS]_3'\right)\end{align}
この損失を逆伝播させてパラメータを学習させる事によって、教師が不十分あるいは全く無い場合でも予測やクラスタリング等が出来るようにしています。
以上が今回のモデルの骨子です。このモデルをベースに
・現在既に弊社の構造化データを元に機械学習モデルでおすすめの求人をレコメンドしているが、そこで使われている特徴量は職種、業種、年収、年齢、学歴、会社規模などの明確に数値化出来るもののみが使われている。を新たな特徴量とすることで、カウンセリングの発話に違いとなって表れてくるであろう性格や志向性、などといった特徴量まで加味したレコメンドが出来る
・と、クレームやNPSスコアを学習させ、満足度の高い/低いカウンセリングを予測する
・各を分類して、カウンセリングの発話の性質を(自己紹介、転職理由、希望条件、各種手続き案内)などに分類して、熟練のCAのカウンセリングの特徴を把握したりCA自身の振り返りに利用する
・各毎にAttentionの大きさを出し、カウンセリングの要約を出す
などといった様々なタスクに転用させていきます。
今回のモデル骨子説明は以上となります。個別のタスクに関しては次回以降の記事で説明していきます。

Y・N
テクノロジー本部 デジタルテクノロジー統括部 データ&テクノロジーソリューション部 アナリティクスグループ アナリスト