

はじめに
doda サイトにて長年運用してきた Solr ベースの検索基盤を、OpenSearch へ移行した際の取り組みをまとめました。 本記事では、全文検索の技術選定とインフラ設計を中心に記載します。 全文検索の導入を検討する方の参考になれば幸いです。
現行のSolrの課題
doda では、求人検索や企業名検索といった機能において、全文検索基盤として長年 Solr を使用してきました。 Solr はコンテナ上で運用していましたが、データ量や構成上の制約によりレプリケーションに時間を要し、即座にスケールアウトすることが難しい状態でした。 そのためピークタイムに備えて、結果的にオーバースペックで稼働させる必要があり、サーバー費用が増加していました。
また運用面では、バージョンアップなどのメンテナンス負荷が高いという課題がありました。 加えて、ログやメトリクスは取得できているものの、管理用 UI 上でインデックスの作成状況などを把握しづらい点や、検索基盤を運用するアカウントの権限管理が煩雑である点も問題となっていました。
これらの課題を解決するため、新しい検索基盤の構築を模索しました。
技術選定
マネージドサービス vs 自前構築
移行を検討する際の最初の論点は「マネージドに寄せるか、自分たちで環境構築するか」でした。 今回は、運用コスト削減と安定したスケールアップを実現したい要望があったため マネージドサービスの選択が自然でした。
Elasticsearch vs OpenSearch
次に全文検索の選択として Solr と同じ Lucene 製であり有名どころとして Elasticsearch と OpenSearch を比較しました。 OpenSearch は Elasticsearch をフォークして作られており AWS がメンテナンスしています。 両者の検索機能に大きな差はないと判断しどちらのマネージドサービスが良いかを検討しました。 Solr についてはマネージドサービスがあまり一般的ではないため除外しました。
Elasticsearch は ElasticCloud というマネージドサービスがあり Elasticsearch の親元である Elastic 社が運営しています。 一方、OpenSearch は OpenSearchService と OpenSearch Serverless の 2 つのマネージドサービスあり、どちらも AWS のサービスです。
それぞれでコスト試算した結果、Elastic Cloud は想定コストが相対的に高くなる見込みでした。 また、doda サイトは AWS 上に構築されていることから、既存環境との親和性やサポートの手厚さを考慮し、AWS 製品を選択しました。
OpenSearch Service vs Serverless
次に AWS の OpenSearch は OpenSearch Service と OpenSearch Serverless を比較検討しました。 OpenSearch Service は、データ量やリクエスト量に応じてノードの台数やスペックを自分たちで設計・調整する必要があります。 一方で OpenSearch Serverless は、インフラ周りの設定が不要で、キャパシティが自動的に調整される点が特徴です。
また、OpenSearch Service はサーバーの稼働時間に応じた従量課金となっています。 一方で OpenSearch Serverless は利用量に応じて請求されますが、厳密には最低確保量が存在し、完全な従量課金ではありません。
私たちは下記の理由からOpenSearch Serviceを選択しました。
- 2024 年 12 月当時 OpenSearch Serverless はリリース直後で事例が少なかった
- Sudachi といった日本語解析プラグイン周りで制約があった
- OpenSearch Service はスケールやシャード・レプリカ数を自分で調整できるため柔軟性を優先
一方でコストが下がるというメリットはあるため将来的に移行の検討はしてもよいと思いました。
データ連携方法の検討
技術選定が完了したら OpenSearch Service へのデータ連携方法を検討します。
OpenSearch Service へのデータ連携方法は複数あります。
- REST API による連携
- Logstash などの OSS の利用
- Amazon OpenSearch Ingestion の利用
- Amazon Kinesis Data Firehose の利用
- S3 Direct Query
Amazon OpenSearch Ingestion は AWS のマネージドサービスで OpenSearch Service 用のデータ収集/取り込みパイプラインです。 コスト体系は OpenSearch Service と同じで動いている間だけ発生します。 複雑なデータ変換や大規模なデータ連携が必要な場合は候補にあがります。 またデータ連携される時間だけの課金となるのでサーバーに上げて REST API や Logstash などの OSS を実行する場合と比べて常時稼働しない分コストを安くできる可能性があります。
Amazon Kinesis Data Firehose は AWS 製のストリーミング ETL ツールで、反映先に OpenSearch Service を指定できます。 ただし、ドキュメントの追加用途が中心で、更新・削除を伴うユースケースには向きません。
S3 Direct Query は、2024 年にリリースされた比較的新しい機能で S3 に配置したデータを直接クエリできるようになります。便利な機能ではありますが、クエリスキャンするデータ量の範囲に比例してコストがかかるのと、インデクシングされないため低レイテンシが求められるアプリケーション検索用途には不向きとされます。 ログ分析などには使えそうだと思いました。
今回の要件としては、(1)リアルタイムの同期が不要であること、(2)連携するデータ量が 10GB と小規模であることが挙げられました。 これらを踏まえ、REST API(bulk)を自作のアプリケーションから呼び出す方式を採用しました。
参考までに、50 万レコード(10GB)の連携データに対して bulk API を使用して 1,000 レコード単位で実行し、10 並列処理でおおよそ 30 分ほどでインデクシングが完了しました。 (インフラスペックによって変わるのであくまで参考値としてください)
OpenSearch Serviceのインフラ設定
OpenSearch Service の設定周りで特に重要な下記設定を紹介します。
- ノード
- マルチ AZ の有無
- シャード数
- 専用マスタノードの有無
- ストレージ
ノード
ノードとはサーバーの台数を指します。 ノードの台数が増えるほど、並列処理数が増えるため検索機能と書き込み性能が向上します。 ノードにはデータノードとマスタノードの 2 種類が存在します。 データノードが検索の実行やデータを保持するノードであるのに対してマスタノードはインデックスの作成やシャードの配置といった全体を管理するノードです。 デフォルトではランダムに 1 台データノードがマスタノードを兼ねるのですが、専用のマスタノードを立てることもできます。
AWS のベストプラクティスでは、ノード台数は3台以上が推奨されています。また後述するシャード数によってノードの台数を変えたほうが良いケースもあるのでそちらは次で説明します。
マルチAZの有無
可用性を高める目的でノードの配置先を複数の AZ に分けることは推奨されています。公式ドキュメントやベストプラクティスでは、可用性の観点から 3AZ 構成が一般的とされています。3AZ にした場合はノードの数を 3 の倍数にすると均などに配置できるのでより良いとされています。
シャード数
シャードとはインデックスのデータ分割単位で、プライマリとそのコピーであるレプリカをインデックスごとに指定します。 例えば、A インデックスを 5 シャード 1 レプリカで指定した場合、インデックスデータは 5 つのプライマリシャードに分割されます。 それぞれに対応するレプリカが作成されるため、合計で 10 個のシャード(5 プライマリと 5 レプリカ)が作成され、プライマリとレプリカは必ず別のノードに自動配置されます。 別のノードに配置されることで 1 つのノードが障害になっても別のノードに置いてあるレプリカがプライマリに昇格するので可用性が担保されます。
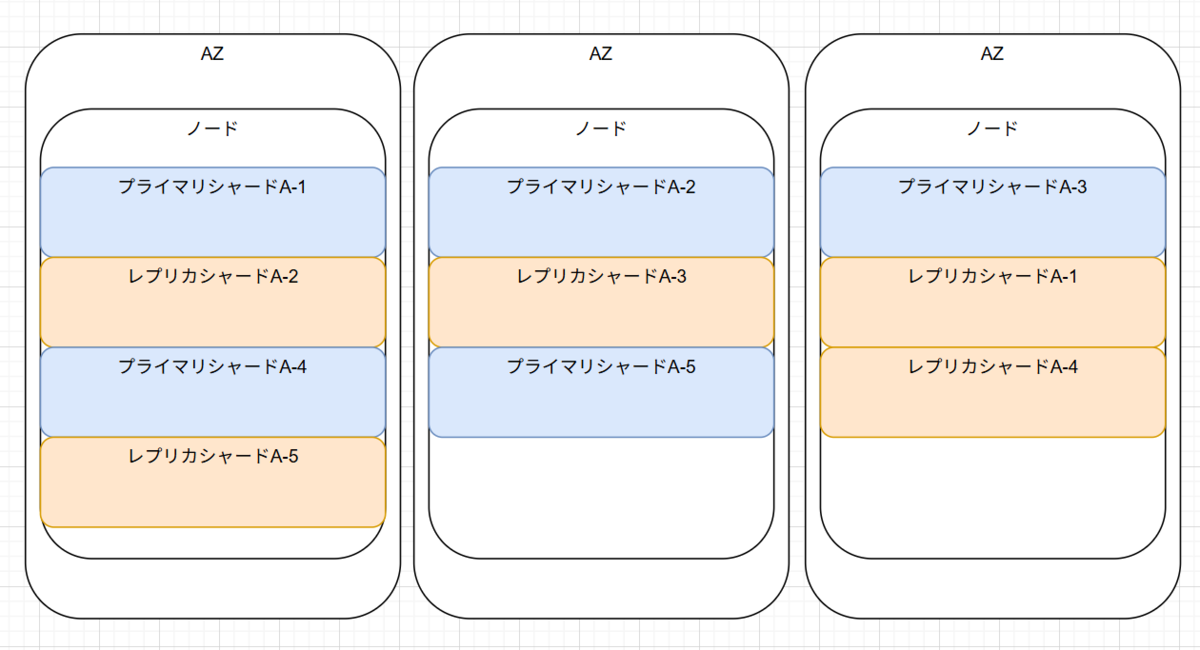
シャード数を設定するにあたってまず重要な指標が、1シャードあたりデータ量を10~30GiBにすることが推奨されています。例えばインデックスのデータ量が 300GiB になる場合 10 シャードを指定するといった具合です。
またレプリカの数についてはマルチ AZ の数-1 を設定するとよい場合が多いです。 さきほどのプライマリとレプリカが別々のノードに配置される話でノードへのシャードの配置は極力均等になっていた方がよいためです。 不均等である場合、特定のノードに処理集中する可能性がありパフォーマンス低下の恐れがあるからです。 マルチ AZ の数-1 でなくとも全体のシャード数*レプリカ数がノード台数で割り切れると均等に配置されやすいです。

専用マスタノードの有無
さきほど、デフォルトではデータノードの中から 1 台マスタノードが選ばれると説明しましたが、専用のマスタノードを立てることもできます。 専用のマスタノードを立てるメリットは可用性の向上にあり、ノードが落ちた際のレプリカをプライマリに昇格やローリングデプロイ時の Blue/Green 切り替えなどが安定して実行できるとされています。
ただし、専用のマスタノードは一般的には 3 台の専用マスタノードを複数 AZ に分散配置するためインフラコストが結構かかります。 今回はインデックスの作成が 1 日 1 回しか行われないことと、ノード数、インデックス数がまだまだ小規模なことを加味して不採用としました。
ストレージ
ストレージはノード全体の合計値を指定する必要があります。 公式が出している下記の計算式で算出すれば良いです。
ソースデータ * (1+レプリカ数) * 1.45
↑ソースデータはインデックスのデータ量を指します。実際にインデクシングして見ないとわからない部分があるので検証環境で試してみておおよそのデータ量を概算して出力すると良いです。
おわりに
本記事では全文検索の技術選定とインフラ設計を中心に紹介しました。
同じように移行を検討している方の判断材料になれば幸いです。
参考
https://docs.aws.amazon.com/opensearch-service/

奥野堅斗 okuno kento
プロダクト開発統括部 dodaアーキテクト部 doda マイクロサービスG
2022年パーソル入社。フロントエンドのリアーキプロジェクトやdodaマイクロサービスなどdodaの技術負債を解消するプロジェクトに携わっています。趣味はロードバイクと筋トレ