

みなさんこんにちは!デジタルテクノロジー統括部に新卒入社した長谷川智彦です。
データサイエンティスト未経験の新卒社員がデジタルテクノロジー統括部内でどんなことをやっているのか、どのように成長していくのかを記録していくこの企画。今回は前回のTitanic号のデータ分析と機械学習の記事に引き続き、新たに追加で行うことになった分析に関して書いていきます!
前回のTitanic号データ分析の後
さて、前回のTitanic号のデータ分析の記事を一通り書いてひと段落ついた頃、メンター社員からある一言をいただきました。
「前回のLightGBMのモデルはもっと精度をあげれると思うからもう一回やろっか」
この時の僕の脳内によぎった言葉は、(ですよねー!)と。(笑)
「あれ?いやだ〜とかではないんだ」と思った方もいらっしゃると思うのですが、実は僕自身前回の結果にどこか違和感を覚えていました。
というのもLightGBMは勾配ブースティングを用いた分類器で、データ分析コンペのKaggleでも最近よく使われる強力なものなのですが、イマイチ良い精度がでなかったのでどこか活かしきれていないだろうなと感じていたからです。とはいえ前回は一通りのデータ分析の仕方とモデルの構築、評価をやってみることが目的だったのでそのまま放置したのですが、今回アドバイスを受け、再度LightGBMを使用しTitanic号データの生死予測モデルを構築してみました。
前回は何が問題だったのか?
前回Titanic号を使用して作成したLightGBMのF1値とROC曲線(黒の曲線がLightGBMです。)は以下の通りでした。

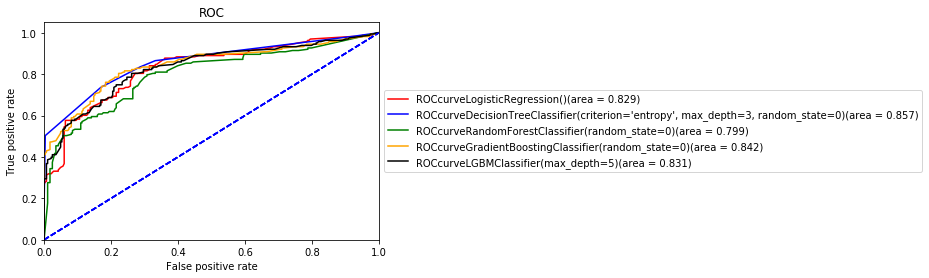
そして先輩社員から示されたコードを元に出た結果が以下の通りとなりました。


前回のどのモデルよりもいい結果が出てきました。ではどうして精度がこのように違ったのかを検討していくと、
1:モデルに学習させたデータセット
2:パラメーターの調整
上記の2点が異なることに気づきました。
ではそれぞれどのように違ったのかをみていきます。
1:モデルに学習させたデータセット
まずはモデルに学習させたデータセットから見ていきます。
A:前回自分で作成したデータセット

B:今回先輩のコードから得られたデータセット

上記に、A:前回自分で作成したデータセットとB:今回先輩のコードから得られたデータセットを示しました。明らかにカラムの数と種類が違います。どうしてこのように違うかというと、前回僕は性別(Sex)と年齢(Age)のカラムからpersonのカラムを作成しまとめ、親子連れかどうか(Parch)と兄弟姉妹といたか(SibSp)のカラムを合わせてFamilyというカラムを作成しました。さらに、名前(Name)、チケット(Ticket)、Fare(乗船料金)、Cabin(客室)、乗船港(Embarked)のカラムを必要がない情報、もしくは他の変数と関連がありわざわざ入れる必要がない情報であると考えたためデータセットから落としました。
しかし、この情報量を落としたことが決定木においてはよくなかったみたいでした。頂いたアドバイスや調べた情報によると、決定木においては情報量が多くても悪影響が少ないため、データを省いたりカラムをまとめたりして情報量を落とすと精度が悪くなるとのことでした。
なので、今回は改めて名前(Name)とPassengerId以外はモデルの学習に使用することにしました。
2:パラメーターの調整
次に違ったのはパラメーターの調整に関してです。Pythonで提供されてる関数にはハイパラメーターという調整できる変数があり、これを調整するとモデルの予測精度がよくなったりします。前回はモデルを構築することが目的だったのでハイパラメーターの調整を行わなかったのですが、頂いたコードはこのパラメーターの一部(n_estimators、learning_rate)が調整されていました。
この2点が違ったため、今回はこの2点を踏まえ、再度LightGBMのモデルの構築に挑戦してみました。
〈先輩のコードから新しく学んだこと〉
頂いたコードを眺めていると便利なコードを見つけました。それはscikit-learnのLabelEncoder()関数です。前回は離散値にしたい変数をmap関数を用いて変換していたのですが、この関数を使用すれば簡単に文字列を離散値に変換できるみたいなので使用してみました。
#scikit-learnからのインポート import sklearn.preprocessing from sklearn.preprocessing import LabelEncoder le = LabelEncoder() for column in ["Sex", "Ticket","Cabin","Embarked"]: #変換したいデータカラムを選択 le.fit(titanic_df[column]) #文字列を離散値に変換 titanic_df[column] = le.transform(titanic_df[column])
このような感じで良いものがあればどんどん真似して使っていこうと思います(万能ではないのでどんな時に使用できるかは気を付けます)。
モデルの構築再挑戦!
さて、それではモデルの構築に再挑戦していきたいと思います。再挑戦において試したことは
1:本当に全てのデータが必要なのか確かめた
2:Optunaを利用してハイパーパラメーターを調整してみた
の2つをメインに行いました。
\\ 全体通してのコード //
#必要なライブラリ等のインポート import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from pandas import Series, DataFrame import lightgbm as lgb from sklearn.model_selection import train_test_split %matplotlib inline #データのクリーニング titanic_df = pd.read_csv("train.csv") titanic_df = titanic_df.drop("Name", axis =1) titanic_df = titanic_df.drop("PassengerId", axis =1) titanic_df["Ticket"] = titanic_df["Ticket"].str[0] titanic_df["Cabin"] = titanic_df["Cabin"].str[0] titanic_df["Cabin"] = titanic_df["Cabin"].fillna("-") titanic_df["Embarked"] = titanic_df["Embarked"].fillna("-") #文字列の離散値への変換 import sklearn.preprocessing from sklearn.preprocessing import LabelEncoder le = LabelEncoder() for column in ["Sex", "Ticket","Cabin","Embarked"]: le.fit(titanic_df[column]) titanic_df[column] = le.transform(titanic_df[column]) le.fit(titanic_df_test[column]) titanic_df_test[column] = le.transform(titanic_df_test[column])
このコードで生成されたデータフレームが以下のデータセットです。

#訓練データ、テストデータの作成 train, test = train_test_split(titanic_df, test_size =0.5, random_state = 0) X_train = train.iloc[:,1:] X_test = test.iloc[:,1:] y_train = train["Survived"] y_test = test["Survived"] #モデルのインスタンス化 model6 = lgb.LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0, importance_type='gain', learning_rate=0.01, max_depth=-1, min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0, n_estimators=1000, n_jobs=-1, num_leaves=31, objective=None, random_state=None, reg_alpha=0.0, reg_lambda=0.0, silent=True, subsample=1.0, subsample_for_bin=200000, subsample_freq=0) #モデルの学習、予測 result = model6.fit(X_train, y_train, eval_set=[(X_test, y_test)],eval_metric= "logloss", verbose = 50, early_stopping_rounds = 200) y_pred1 = model6.predict(X_test, num_iteration = result.best_iteration_) y_pred_proba = model6.predict_proba(X_test, num_iteration=result.best_iteration_)[:,1] importance = pd.DataFrame(model6.feature_importances_, index = X_train.columns, columns=["importance"]) display(importance.sort_values("importance", ascending= False))
ここでLightGBMの構築で判断指標となった変数のimportanceを取得しました。

Loglossの値は0.414973でした。
次に混同行列と適合率、再現率、F1値を計算しました。
#混同行列の作成 matrix6 = confusion_matrix(y_test, y_pred1) print("混同行列(LightGBM):\n{}".format(matrix6)) #適合率、再現率、F1値の計算 from sklearn.metrics import precision_score, recall_score, f1_score print("LightRBMの適合率、再現率、F1値") print("適合率:{:.3f}".format(precision_score(y_test, y_pred1))) print("再現率:{:.3f}".format(recall_score(y_test, y_pred1))) print("F1値:{:.3f}".format(f1_score(y_test, y_pred1)))


最後にROC曲線をプロットしました。
from sklearn.metrics import roc_curve, auc from sklearn import metrics model6.fit(X_train, y_train) y_pred1 = model6.predict_proba(X_test)[:,1] fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred1) auc = metrics.auc(fpr, tpr) plt.plot(fpr, tpr, color = "red", label = "ROCcurve" + str(model6)+"(area = %.3f)"% auc) plt.plot([0,1],[0,1], color = "blue", linestyle = "--") plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel("False positive rate") plt.ylabel("True positive rate") plt.title("ROC") plt.legend(loc='center left', bbox_to_anchor=(1., .5))

1:本当に全てのデータが必要なのか確かめた
今回先輩からのFBを受けて、決定木のアンサンブル学習を行うときはできるだけ情報量を落とさないことが大事であることを学びました。しかし、それでも本当にすべてのデータがあった方が精度が良いのか不思議に感じたため確かめてみることにしました。
実際データを探索していると個人的にチケットのカラムがあまり規則性もなく必要でないと感じたため、このカラムを落としたデータセットを作成しカラムを抜く前の結果と比較しました。

↑チケットカラムをカラムにある項目ごとの数を数えるvalue_count()で処理した結果。バラバラで一貫した文字列には見えなかったので流石に必要ないのではないかと考えました。
チケットを抜いたデータセットが以下のようになります。

先ほどのモデルと同じパラメーター条件で学習を行い、得たlogloss値とimportanceの結果は以下のようになりました。

logoss:0.413353
loglossの値には大きな差は現れませんでしたが、Ticketを抜いたことでEmbarked等の順番が多少入れ替わりました。
引き続き混同行列、適合率、再現率、F1値、ROC曲線の結果を示すと以下のようになりました。



先ほどの結果と比較してみると全ての値において大きく変わることはありませんでしたが、Ticketカラムが入っている方がわずかにROC曲線の面積値が良い結果となりました。あってもなくても良いのではないかと感じましたが少しでも精度の良い方にしようと考え、今回はチケットカラムを入れて引き続き分析を行なっていきました。
2:Optunaを利用してハイパーパラメーターを調整してみた
それではここからはハイパーパラメーターの調整について書いていきます。ハイパーパラメーターとはざっくり言えば機械学習の動き方を調整する設定のようなものです。最適な部屋の温度にする際にエアコンの温度を上げ下げすると思うのですが感覚的にはこれに近いと個人的には思っています。(正確には数学的なモデルに基づいて調整するべきものです。)データ分析コンペであるKaggleにおける職人レベルの方々は手動でこの値を調整されているらしいのですが、今回はハイパラメーターの調整法を勉強している際に見つけたOptunaという最適なハイパラメーターを探してくれるライブラリを使用してみました。
しかし、どのパラメーターを調整すれば良いのか迷ってしまったので、初めにLightGBMの公式ドキュメントにおいて、より精度を出すために調整すると良いパラメーターに挙げられていたmax_bin、num_leaves、learinig_rateと、アドバイスで調整したら良いと教えてもらっn_estimatorsのパラメーターの最適値をOptunaで探すとともに、LightGBMのboosting_typeのパラメーターにおいて"dart"と"gbdt"をそれぞれ試してみました。以下にOptunaで調整した際のコードと結果、また、boosting_type="dart"と”gbdt”で比較した結果を載せます。
Optunaでのパラメーター探索のコード
import optuna import lightgbm as lgb def objective(trial): params = { 'max_bin': trial.suggest_int('max_bin', 100,300), 'num_leaves' :trial.suggest_int("num_leaves", 20, 50), 'learning_rate' :trial.suggest_loguniform("learning_rate", 1e-3, 1e-1), 'n_estimators' :trial.suggest_int('n_estimators', 100, 10000), } clf = lgb.LGBMClassifier(boosting_type='dart', **params, random_state=0) clf.fit(X_train, y_train) return clf.score(X_test, y_test) study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=3) print('Best trial:', study.best_trial.params)
Best trial: {'max_bin': 178, 'num_leaves': 36, 'learning_rate': 0.0043547026648520885, 'n_estimators': 2629}
作成したモデルのコード
#dart Ver. model8 = lgb.LGBMClassifier(boosting_type='dart', class_weight=None, colsample_bytree=1.0,max_bin = 178, importance_type='gain', learning_rate=0.0043547026648520885, max_depth=-1, min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0, n_estimators=2629, n_jobs=-1, num_leaves=36, objective=None, random_state=None, reg_alpha=0.0, reg_lambda=0.0, silent=True, subsample=1.0, subsample_for_bin=200000, subsample_freq=0) #gbdt Ver. model9 = lgb.LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,max_bin = 178, importance_type='gain', learning_rate=0.0043547026648520885, max_depth=-1, min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0, n_estimators=2629, n_jobs=-1, num_leaves=36 ,objective=None, random_state=None, reg_alpha=0.0, reg_lambda=0.0, silent=True, subsample=1.0, subsample_for_bin=200000, subsample_freq=0)
dart設定で得られた混同行列、適合率、再現率、F1値とROC曲線


gbdt設定で得られた混同行列、適合率、再現率、F1値とROC曲線


ROC曲線の面積値だけを見れば教えてもらったものよりもわずかに精度が良くなった気がします。
ただ、モデルを構築する際に出てきたdartやベイズ最適化に関してちゃんと知識を持っていないので今後勉強することリストに追加しておきます。
さて、パラメーターも最適化できたのでここで先輩社員にFBをいただきました。すると次のようなアドバイスをいただきました。
「learning_rateとn_estimatorsさえいじれば良い値に落ち着くよ、あとn_estimatorsを大きくする場合はearly stoppingを入れるといいよ」
(あれ、公式ドキュメントにはこれ以外にも色々書いてあったのに、、、)と個人的には半信半疑でアドバイスをメモしていたのですが、実際にアドバイスされた2つだけを調整してみることにしました。この際に修正したコードが以下の通りです。
import lightgbm as lgb import numpy as np from sklearn.model_selection import train_test_split import optuna def objective(trial): n_estimators = trial.suggest_int('n_estimators', 100, 10000) learning_rate = trial.suggest_loguniform("learning_rate", 1e-4, 1e-1) clf = lgb.LGBMClassifier(n_estimators=n_estimators, learning_rate=learning_rate, random_state=0) clf.fit(X_train, y_train) return clf.score(X_test, y_test) study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=3) print('Best trial:', study.best_trial.params) model10 = lgb.LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0, importance_type='gain', learning_rate=0.001837794725707605, max_depth=-1, min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0, n_estimators=1432, n_jobs=-1, num_leaves=31, objective=None, random_state=None, reg_alpha=0.0, reg_lambda=0.0, silent=True, subsample=1.0, subsample_for_bin=200000, subsample_freq=0) #残りのコードは上記と同様になります。
Optunaでlearning_rateとn_estimatorsを自動調整して得られた結果が
![]()
そして、得られたパラメーターをモデルに代入し、得られた混同行列、適合率、再現率、F1値、ROC曲線が次のようになりました。


また、ざっくりとlearning_rate = 0.001、n_estimators = 1000と設定してモデルを学習させたコードと結果が以下のようになりました。
model12 = lgb.LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0, importance_type='gain', learning_rate=0.001, max_depth=-1, min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0, n_estimators=1000, n_jobs=-1, num_leaves=31, objective=None, random_state=None, reg_alpha=0.0, reg_lambda=0.0, silent=True, subsample=1.0, subsample_for_bin=200000, subsample_freq=0) #残りのコードは上記と同様になります。


さて、実際にlearning_rateとn_estimatorsだけを調整してみましたが、確かに他のパラメーターをいじらなくても結果は先ほどと同じか近いAUC面積の値になりました。この理由を伺うとlearning_rateとn_estimatorsで学習のスピードと回数を決めてしまえば、ブースティングにおいては設定したパラメーター条件内で最適な答えにたどり着くまで学習を繰り返し行うので、他のパラメーターを調整せずとも最終的な結果に大きな差が生まれないとのことでした。またハイパラメーターをむやみにいじるよりはデータセットの前処理を丁寧に行なった方がいいとのことだったので今後はデータのクリーニングにより時間を割こうと思います。
今回の総評
今回アドバイスを受けて再度LightGBMのモデルの構築を行いました。
感想としては、
・アンサンブル学習において情報量を落とすことはよくないことがわかった
・ハイパラメーターの調整よりは如何にデータセットをきっちりと整える方がいいというコメントの真意を体験できた
・ハイパーパラメーターの調整においてどのパラメーターを調整するかはしっかりとした数学的モデルの理解がないと難しいと感じた
・learning_rateとn_estimatorsをいじれば大方うまくいくことは意外であった
と言った感じです。
ハイパーパラメーターを調べている上でベイズ最適化などまだしっかりと理解できていないことなども出てきたのでこれから勉強していこうと思います。
では今回はここまでです。次回の研修記事もお楽しみに!

長谷川 智彦 Tomohiko Hasegawa
デジタルテクノロジー統括部 データ&テクノロジー ソリューション部 アナリティクスグループ
大学時代の専攻は植物学・分子生物学。最近趣味でデザインをかじり出した社会人1年目。植物の実験データを正しく解釈するために統計を勉強し始め、データ分析に興味をもつ。データサイエンスはただいま必死に勉強中。
※2020年7月現在の情報です。