

こんにちは、今年4月からデジタルテクノロジー統括部に新卒入社した長谷川智彦です。
僕たちの学びの過程を定期的に配信する『データサイエンティスト育成日記』、前回はオンライン講座を元にKaggleのTitanic号データの分析に関して記事を記載しましたが、今回は自分たちの視点でどのようにデータを分析していったかについて書いていきます!
Titanic号データ分析を自分たちで挑戦!
実際に、自分たちでデータ分析ができるようになるかどうかを確かめるために、Titanicコンペのデータを使用してデータ分析を示していきます。
データ分析の流れをこのように考えてみました。
Titanicデータの分析の流れ
- データの確認と探索、仮説の設定、検証
- 予想モデルの構築、評価
それぞれ見ていきたいと思います。
データの確認と探索、仮説の設定、検証
始めはTitanicデータが具体的にどんなデータで構成されているかをものかを見ていきました。Jupyter notebook を使用してcsvファイルを開いてみると…。

はい、数字と文字がいっぱい出てきましたね。このままではさすがにわかりづらいのですが、先に今回記事で扱う主要なデータのカラムの説明だけ書いておきます。
〈カラムの説明〉
PassengerId:乗客のId番号
Survived:生存を表すカラム、0 が亡くなった人、1 が生存した人を示します
Pclass:チケットランクを表しています。1:上層クラス、2:中級クラス、3:下層クラスを表します
Sex:性別
Age:年齢
Embarked:乗船した港、Sはサウサンプトン(イギリス)、Cはシェルブール(フランス)、Qはクィーンズタウン(アイルランド)
このデータセットを元にいろんなグラフを作成し各変数の関係性を調べていったのですが、すべてを書いていくと記事が長くなるので調べた中で面白いと感じた生存者(Survived)と乗船港(Embarked)、チケットクラス(Pclass)間の関係を載せたいと思います。
まず、各変数ごとに生存者数との関係がどのようになっているかを調べていったところ、乗船港と生存者数において次のような結果が得られました。
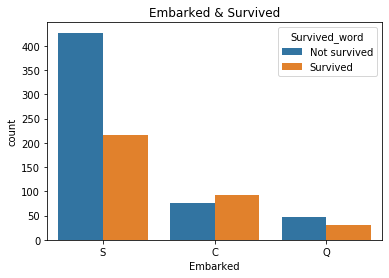
このグラフを見るとサウサンプトンから乗った人々の生存率は他と比較して低いことがわかります。しかし、乗船港が生存率を左右するとは到底思えません。となると、この結果に結びつく理由が乗船港と生存率の間に介在することになります。実はこの結果を得る前に次のことがわかってました。
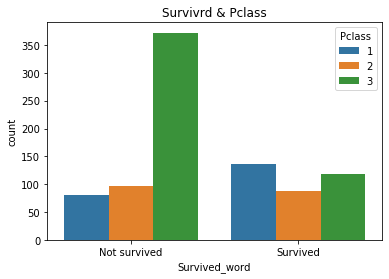
チケットランクと生存者の関係において上記のグラフのように非生存者におけるチケットランク3(当時低階級の乗客が多く乗っていた)の占める割合がとても多いことがわかりました。理由としては階級の高い乗客が多かったランク1 や2 の乗客が優先して救出されたか、救出されやすい環境であったことが考えられます。この結果と先ほどの乗船港と生存者の結果を踏まえると、次のような仮説が考えられます。
仮説:各都市で乗船した乗客の階級が違うため、乗船した乗客の階級の違いが乗船港と生存者数の結果に表れたのではないか。
それではこの仮説を確かめるために乗船港、チケットランク、生存者数をもとにグラフを作成してみた結果が次のグラフです。
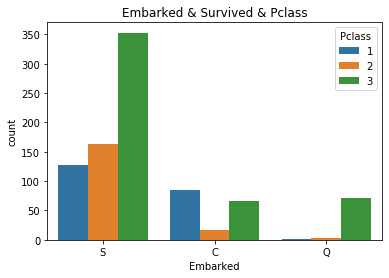
この結果を見ると、
サウサンプトン:全体的に乗船したお客の数が多く、かつ下層クラスの乗客がかなり多く乗っていた。
シェルブール:乗船客の内、上層クラスと下層クラスが多い。
クィーンズタウン:乗船客のほぼすべてが下層クラスであった。
以上のことがわかりました。
このことから、サウサンプトンではチケットランク3 の乗客の乗船者数が多く、チケットランク3 の人々の生存率は低かったため、このことが乗船港と生存者数の結果に表れたことが考えられます。
これに加え、個人的にはどうしてサウサンプトンからの乗客が多く、また、クィーンズタウンでの下層クラスの乗客が多かったのかが気掛かりだったため当時のタイタニックの航路と各都市の時代背景をネットで調べてみました。まず、タイタニック号はサウサンプトンから出港し、シェルブール→クィーンズタウンの順で航海していたそうで、サウサンプトンでの乗客が多かったのは出発港であったことが考えられます。そして、クィーンズタウンで乗客のほとんどが下層クラスであったことに関しては、確証はありませんが、このころクィーンズタウンが位置するアイルランドでは大飢饉があったらしく多くの移民が出たそうです。このことを踏まえると、クィーンズタウンからの乗客はその移民だった可能性も考えられます。
このように、得られたデータの結果と合わせて様々な情報を集めるとデータだけではわからないことも見えてくるのはかなり楽しかったです。
「データの確認と探索、仮説の設定、検証」を通じて、データの結果だけではわからないことも見えてきて、改めてその重要性を感じました。
引き続き次回はTitanic号データの予想モデルの構築・評価について書いていくのでお楽しみに!

長谷川 智彦 Tomohiko Hasegawa
デジタルテクノロジー統括部 データ&テクノロジー ソリューション部 アナリティクスグループ
※2020年6月現在の情報です。