

こんにちは!今年4月にデジタルテクノロジー統括部に新卒入社した長谷川智彦です。いよいよTitanic号データの分析研修を紹介するラストの記事となりました。
前回の記事ではデータの探索と仮説の検証を行っていきましたが、今回はデータを使用して予想モデルを構築、評価した内容についてお伝えします!
2:予想モデルの構築、評価
機械学習ではデータを数学・統計学に基づく数理モデルに代入し、結果を予測するといったことを行います。今回はすでに知られている数理モデルの中から以下の5つを使用してモデルの訓練とデータの予測を行いました。
使用した数理モデル
重回帰分析:sklearn.linear_model のLogisticRegression
決定木:sklearn.tree のDicisionTreeClassifier
ランダムフォレスト:sklearn.ensemble のRandomForestClassifier
勾配ブースティング:sklearn.ensemble のGradientBoostClassifier
LightGBM:sklearn.lightgbm のLGBMClassifier
(今回はパラメーターの調整等は細かく行ってないです。)
まずは、モデルに入れるデータのクリーニングを行います。
データの中には分析にあまり必要がないデータや欠損、重複したデータがあるのでこれらを除いたり、違う値を代入したりして整えていく必要があり、これらの作業を行うことをクリーニングと呼びます。
ただ、このデータのクリーニングは作業の大半を奪ってしまうと言われるほどややこしいものと言われてまして、実際僕自身もコードを叩いていて何度もエラーコードを叩き出しました…。
ではこれから、僕がどのように考えデータフレームを整えたのかを書いていきますね。
(新卒研修を担当されている方はこんなとこでつまずくんだな、と温かく見守ってください!)
今回は Titanicデータの中で、生存したか(Survived)、チケットランク(Pclass)、年齢(Age)に加え、person(15歳以下を性別問わずchild とし、15歳以上で男性をmale、15歳以上で女性をfemale として分類したもの)とFamily(兄弟姉妹が一緒にいたかを表すSibSp と親子づれであったかを表すParch を足し合わせ、家族の誰かがいればWith Family、一人であればAlone とラベリングしたもの)を新しく作成し、モデルを学習させるためのデータとして用いました。ここにおけるperson とFamily のカラムはUdemy の講座を真似して作成したのでつまずきはしませんでした。
次にこのデータセットから、生存者の予測に関係しそうな変数、関係しなさそうであるもしくはカラムをまとめたので今回はいらないと判断した変数に整理しました。
〈予測に必要と感じた変数〉
生存したか(Survived)、チケットランク(Pclass)、年齢(Age)、person(Sexにおける性別に加え、15歳以下をchildと割り当てたもの)、家族の有無(Family)
〈予測に必要でないと感じた変数〉
PassengerId、名前(Name)、チケット番号(Ticket)、乗船料(Fare)、船室(Cabin)、乗船港(Embarked)
これらをもとに必要と感じたカラムだけを残したのが以下のデータフレームです。

この時点でperson カラムやFamily カラムが文字型だったので、これを整数に変換したいなと考えました。かつ、これらをダミー変数化(数字ではないデータを0 と1 に変換した数値のこと)したいと考えたので、本やネットでダミー変数化のやり方を調べ、実際に行いました。その結果が以下のデータフレームです。
dummy_titanic_df = pd.get_dummies(titanic_df_for_machine_learning) dummy_titanic_df.head()
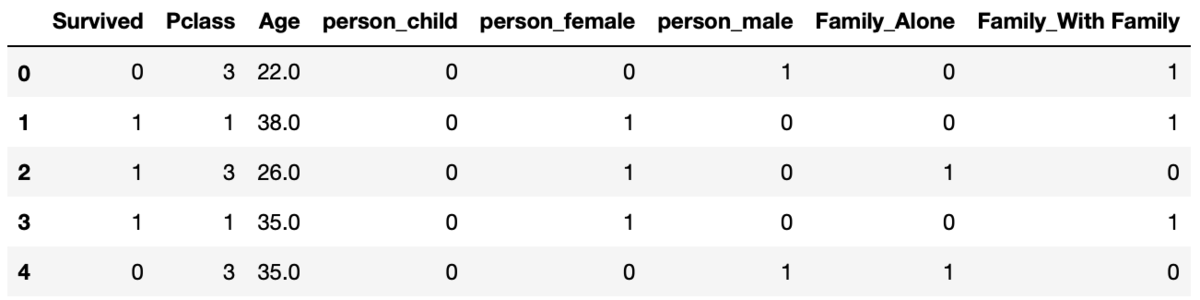
ここでダミー変数化できたと考えた僕はこれを予測モデルに入れました。
ただ、予測モデルに入れた後に先輩に見て頂いた後のフィードバックでこのダミー変数の作り方について「このやり方はあまりよくないね」と教えてもらいました。
なぜ良くないのかといいますと、例えばこのダミー変数だと、男性、女性、子供それぞれに対して0 か1 を割り振っています。ただよく考えてみると、男性のカラムでは1 は男性を表し0 は女性または子供を表しています。つまり、男性カラム内の0 または1 で男性と女性もしくは子供の区別はできているのに、これに加えて女性と子供においても同様に0 と1 でそれぞれダミー変数を作ってしまっては同じ意味を表す情報を複数のカラムでモデルに与えていることになります。(Family のカラムのダミー変数においても同様です。)
これを改善しようということで、次はmap 関数を使用し、personカラムにおいてはmale:0、female:1、child:2 と変換し、Family カラムにおいてもWith Family:0、Alone:1 と変換しました。変換を行った後に目的変数のみをまとめたのが以下のデータフレームです。
titanic_df_for_machine_learning["person"] = titanic_df_for_machine_learning["person"].map({"male":0, "female":1, "child":2}) titanic_df_for_machine_learning["Family"] = titanic_df_for_machine_learning["Family"].map({"With Family":0, "Alone":1})

関数を使ってダミー変数化するのはいいことですが、出てきた結果をしっかりと検討する必要があると感じました。
それでは、整えたデータを使用して実際にモデルの学習を行っていきます。以下のコードで行っていきました(書いてから途中をfor文で処理すればいいことに気づいたので次からは先にどのようにコードを書くか考えたいです)
#ライブラリのインポート from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier import lightgbm as lgb from sklearn.metrics import confusion_matrix from sklearn.model_selection import train_test_split #訓練データと教師データの用意 X = titanic_learn Y = titanic_target X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size =0.5, random_state = 0) #インスタンス化 model2 = LogisticRegression() model3 = DecisionTreeClassifier(criterion = "entropy", max_depth=3, random_state = 0) model4 = RandomForestClassifier(random_state = 0) model5 = GradientBoostingClassifier(random_state = 0) model6 = lgb.LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0, importance_type='split', learning_rate=0.1, max_depth=5, min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0, n_estimators=100, n_jobs=-1, num_leaves=31, objective=None, random_state=None, reg_alpha=0.0, reg_lambda=0.0, silent=True, subsample=1.0, subsample_for_bin=200000, subsample_freq=0) #モデルの学習 model2.fit(X_train, Y_train) model3.fit(X_train, Y_train) model4.fit(X_train, Y_train) model5.fit(X_train, Y_train) model6.fit(X_train, Y_train)
ここで、重回帰分析に関しては各変数の回帰係数を表示し、決定木に関しては可視化にも挑戦してみました。
まず、重回帰分析の変数と回帰係数を表した結果が以下になります。
print("決定係数(test):{}".format(model2.score(X_test, Y_test))) print(X_test.columns) print("\n回帰係数\n{}".format(model2.coef_))

この回帰係数(変数と回帰係数の値の順番は対応しています)を見ると、
チケットランク:値が1~3 と増えるほど、つまり客室の質が下がるほど生存率が下がることを示しています。
年齢:影響が小さいですが年齢が上がるにつれ、生存率に正の影響があります。
person:値が1、2とあるにつれ生存に生の影響があることが見れます。おそらく、女性(1)、子供(2)が優先して救出されたからだと考えられます。
Family:影響度は小さそうですが生存に正に影響していそうです。
このように変数の係数の正負や値の係数の大きさで各変数がどのように影響するのかがわかってきます。
次に決定木の可視化に関してです。
今回最終的にgraphvizを使用して以下のコードで決定木の可視化を行いました。
#ライブラリのインポート import pydotplus from sklearn.tree import export_graphviz from io import StringIO from sklearn import tree from IPython.display import Image #決定木の可視化 dot_data = StringIO() tree.export_graphviz(model3, out_file=dot_data) graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) Image(graph.create_png())
しかし、初めはdtreeviz というライブラリを見つけたので以下のコードを参考に修正して使用しようとしていました。
from dtreeviz.trees import dtreeviz viz = dtreeviz( clf, titanic_learn, titanic_target, feature_names=["Survived", "Not Survived"], ) viz.view()
しかし、各パラメータを修正していたところ、1つだけどう修正してもerror が出てしまうところがありました。それは、feature_name のパラメーターです。初めはここは分類先のラベルを入れればいいと考えていたので上記のコードのようにしていたのですが、error が出てしまいました。その後もデータフレームのカラム名を入れてみたりといろいろと試したのですが、目的は決定木の可視化ではなくモデルの構築と評価だったこともあり、今回は飛ばしてしまいました。再度勉強してどうすればいいのかわかれば再度時間を作って挑戦しようと思います。
ひとまず、graphviz を利用して可視化を行ってみたところ、次の結果が得られました。

少し見づらいですが、これを見ると初めに男性か女性か、子供で分けた後に、チケットランクで分け、最後に年齢で分けています。
決定木の良さは分類の際にどの変数がどのように判断に使用されたのかが目に見えるとこだと感じました。
こんな風にいろいろと細かいミスを重ねながらも(他にも分類を行いたいのにRandomForestClasifierではなくRandomForestRegressorを選んでいたりとか)一通りモデルを組むことができました。他の研修があったとは言えこの作業に3日かかったので1日でできるように頑張ります。
モデルが組めた後はデータを訓練用データとテスト用データに分割し、モデルに学習させ、交差検証を行い、正答率を計算してみました。その結果が以下のようになります。(パラメーターのcv はアドバイスを受けて5 に設定)

交差検証を行った結果ではLight GBMが最も正答率が高くなりました。
また、モデルの正答率は出たけれど、モデルをどのように評価すべきか迷い先輩に相談したところ、混同行列を作成しF1 値とAUC 曲線を出すといいとアドバイスを受けたのでモデルの適合率、再現率、F1 値とAUC曲線をだしてみました。

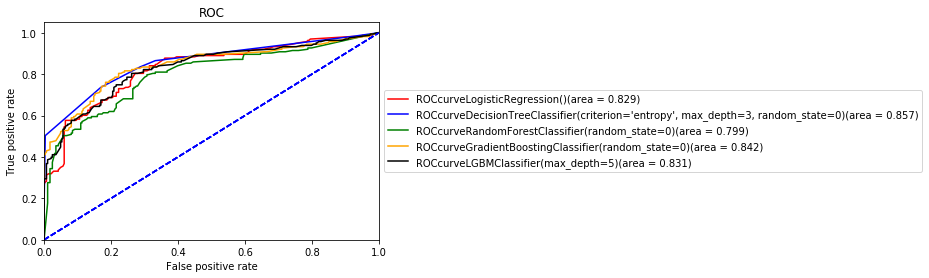
AUC曲線を見ると今回使用したモデル間で大きな差は見られないことがわかります。AUC曲線は曲線と軸に囲まれた下の部分の面積が1 に近いほど予測の精度がいいことを表すのですが今回はどれも0.8‐0.86となり、まずまずの精度かなと感じます。今回面積が一番大きかったのは決定木でしたが、パラメーターの検討をしていけばLight GBMあたりが一番精度が良くなるのかもしれないなと感じました。ここのモデルの選別を皆さんどうしていらっしゃるのかが気になったので、今後アドバイスをもらおうと思います。
AUC曲線の面積の結果から、今回は決定木をモデルとして選択し、最後にKaggleに結果のcsvファイルを提出して順位を確かめてこの研修を終えました。結果は、
19000位代、、、。正答率が同じ方がとても多くいたので皆さん同様の練習を行っているんだなと感じました。今後は本格的にコンペに参加してメダルを獲れるように実力をつけていこうと思います。
オンライン講座研修の総評
全3回に分けてお送りしたオンライン講座研修、いかがでしたか?
僕自身はこの研修を受けてみて、こんな感想を持ちました。
- レベル感としては適切な難易度でちょうど良く、これまで勉強したことを再確認できた
- 一通りの基本的なモデルの組み方は理解したが、パラメーターのチューニングなどを行ってないのでこれからどうやるか調べていきたい
- やっぱりデータが可視化されるのは見ていて楽しい。でもデータのクリーニングは正直めんどくさかった
- 参考書でモデルの原理を学んでいると結果の解釈の仕方もわかるので、勉強を続けることは大事
他にも研修課題があるのでこれらの研修に関しての記事も書いていきますが、研修で様々な分野に挑戦ができて楽しく研修できるので、デジタルテクノロジー統括部のデータサイエンティストでの業務に興味がある方はぜひ参考にしていただけると嬉しいです。
(実は個人的にオウンドメディアの記事執筆もしたかったので夢が一つ叶いました!)
それでは次回の育成日記もお楽しみに!

長谷川 智彦 Tomohiko Hasegawa
デジタルテクノロジー統括部 データ&テクノロジー ソリューション部 アナリティクスグループ
※2020年6月現在の情報です。