
はじめに
現代企業の中で、業務効率向上のためには、膨大な社内情報を効率的に管理し、迅速にアクセスする能力が必要です。特に、ExcelやPowerPointのような非構造化データを含む社内文書の検索は、知識管理の重要な課題となっています。弊社では、この課題に対応するため、 社内向け生成AIチャットサービス に RAG(Retrieval-Augmented Generation) の仕組みを導入し、社内文書から自動的に回答を生成する機能を実装しました。
このサービスは、2024年3月に ベータ版をリリース し、約半年後の 9月には正式版 をリリースして、検索精度や対応する文書範囲を大幅に改善しました。今回の記事では、社内文書検索機能の改善経緯と、正式版リリース後に導入した LLM-as-a-Judge について詳しく紹介します。
これまでの関連取り組みとして、まず リリース当初 の話については以下の記事でご覧いただけます。
また、社内文書検索機能のベータ版リリース に関する詳細は、こちらの記事をご参照ください:
目次
- リリースの背景
- ベータ版リリースから正式版への改善
- 社内文書検索機能の正式版リリース
- LLM-as-a-Judge導入の必要性
- RAGシステムの評価と課題
- 今後の展望
リリースの背景
弊社では、過去にルールベースのボットサービスを提供していましたが、定型的な情報しか回答できず、増加する社内データに対応することが困難でした。そこで、生成AI技術を活用し、社内文書から動的に情報を取得・生成するチャットサービスの開発を進めました。
「Azureで社内文書から回答可能な生成AIチャットサービスを作った話」にもある通り、新しいデータに対応する柔軟な検索が求められていた背景から、 RAG(Retrieval-Augmented Generation) を用いた社内文書検索機能のベータ版を2024年3月にリリースしましたが、検索精度や対応する文書範囲の改善が課題となりました。
ベータ版リリースから正式版への改善
ベータ版リリース後、特に以下の課題が浮上しました:
- 対象文書の範囲:ベータ版では、検索対象が手動で連携されたファイルに限定されており、実際のニーズに十分に応えられませんでした。
文書検索精度自体に大きな問題はありませんでしたが、対象とする文書範囲の拡張が必要でした。そこで、正式版では以下の改善を行いました:
- 対象文書の自動連携:Microsoft SharePoint上の文書を自動的に取り込む仕組みとして専用のパイプラインを導入し、手動連携の負担を解消しました。
- ファイル転送ジョブの自動化:文書がAzure Blob Storageに自動転送され、最新のデータに基づいた検索が可能に。
なお、正式版としてリリースしていますが、今回は「全社員がアクセス可能なファイルデータ」に限定しているため、事業部固有のデータやプライベートなファイルは含まれていません。今後は、 Azure AI Searchのインデックスを切り分ける ことで、事業部別やその他セグメンテーションによる検索対象の調整も検討しています。
社内文書検索機能の正式版リリース
正式版では、 ベクトル検索 と フルテキスト検索 に セマンティックランカー を組み合わせた セマンティックハイブリッド検索 を採用しています。この検索手法では、ベクトルフィールド(埋め込み)とフルテキスト検索を並行して処理し、 Reciprocal Rank Fusion (RRF) アルゴリズムでスコアリングした結果セットを提供します。また、セマンティックランカーがクエリの意味を解釈し、より文脈に即した検索結果を優先的に表示します。
このハイブリッド検索の詳細については、Microsoft公式ドキュメント をご参照ください。ベクトル検索とフルテキスト検索を組み合わせ、文脈や意味に基づいた検索結果を得ることが可能です。
アーキテクチャ
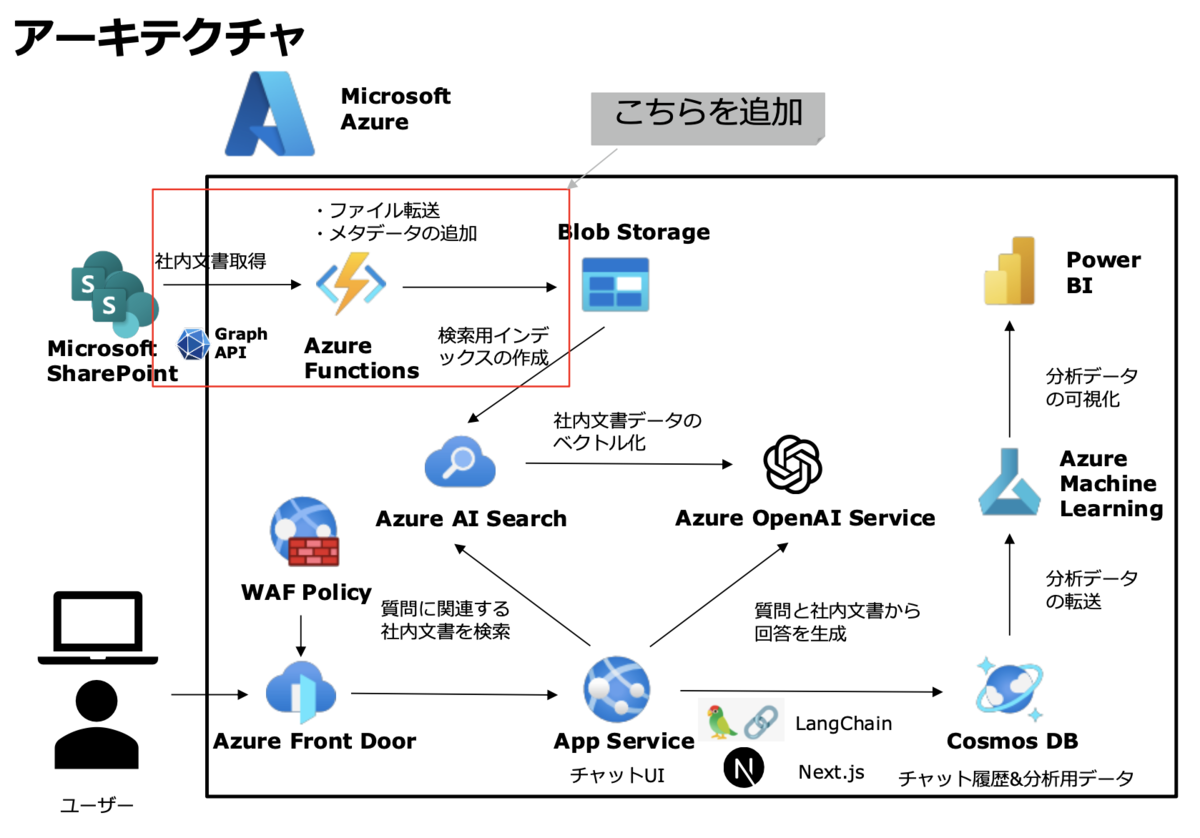
選定技術

今回の正式版リリースでは、ベータ版「参照:Azureで社内文書から回答可能な生成AIチャットサービスを作った話 」から以下の技術が追加されています:
- Azure Functions と Pythonスクリプト:データ転送パイプラインに導入され、Microsoft SharePointからAzure Blob Storageへの文書転送を自動化する仕組みを構築しました。
- Pytestによるテスト自動化:データの正確性を定期的に確認し、文書の転送や更新が安定的に行われるよう、品質管理を強化しています。
転送の仕組み
SharePointからAzure Blob Storageへのファイル転送ジョブを構築し、2つのリソース間でファイルデータに差分が生じた場合、その差分をBlob Storage側に反映させる同期システムを導入しました。
- SharePoint側にのみ存在するファイルはBlob Storageにアップロード
- Blob Storage側にのみ存在するファイルは削除
- 更新日時が新しくなっているファイルはアップロードし直し
ファイル転送ジョブは クライアントクレデンシャル認証 によってSharePointにアクセスし、セキュリティとアクセス制御を確保しています。また、Azure Blob Storageの各Blobにメタデータとして file_id や SharePoint上のファイルへのリンクを含ませ、これらのデータがAzure AI SearchのSkillsetを経由して最終的にAzure AI Searchのインデックスにfield mappingされる仕組みを整備しました。
LLM-as-a-Judge導入の必要性
正式版リリースにより検索機能の精度や利便性は向上しましたが、社内文書の量が今後さらに増加することを見越すと、手動で生成された回答や検索結果を評価することには限界がありました。特に、膨大な文書に対する一貫性の維持やリソースの確保が課題です。そこで、 LLM-as-a-Judge の導入を決定しました。
LLM-as-a-Judge による自動評価システムを導入することで、以下の利点があります:
- スケーラビリティ:社内文書が今後さらに増加・変動することを前提に、短時間で大量データの評価が可能となり、増減する文書に対応できる柔軟性を確保。
- 一貫性の維持:生成された回答や検索結果を、自動的かつ一定の基準に基づいて評価することで、評価プロセスの一貫性を高めます。
- リソースの最適化:従来の手動評価から解放され、人的リソースを他の業務に集中させることが可能です。ただし、現状では完全に手動評価が不要になるわけではなく、定期的な人手による評価(ヒューマンインザループ)も引き続き必要です。
RAGシステムの評価と課題
RAGシステムの評価指標についての補足説明
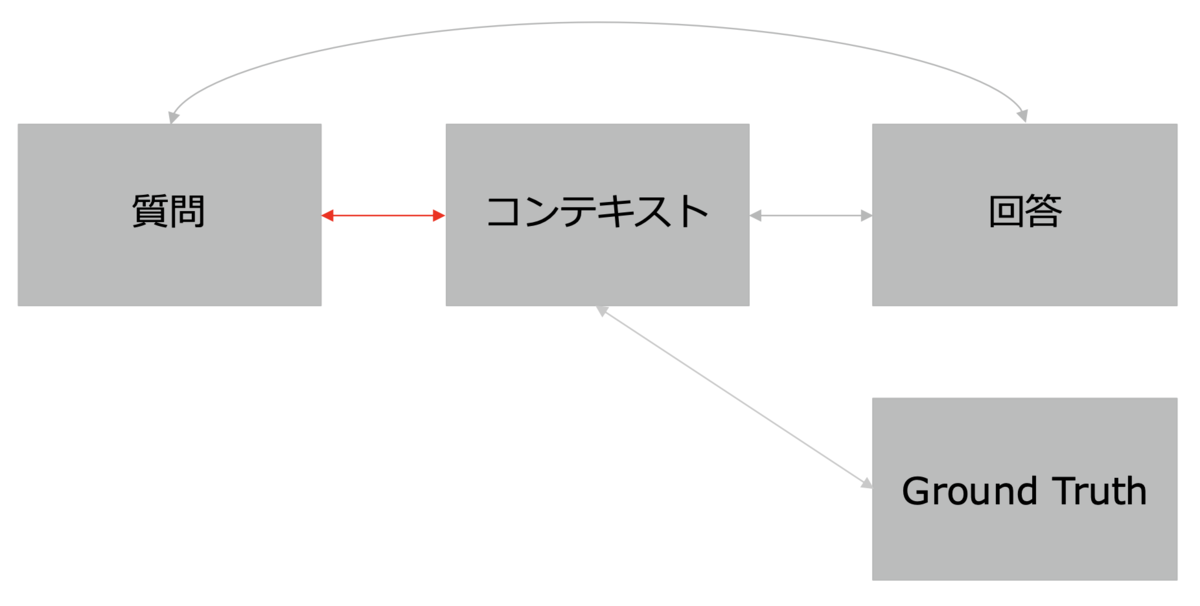
- Faithfulness(忠実度):生成された回答が元の文書やデータにどれだけ忠実であるかを評価します。
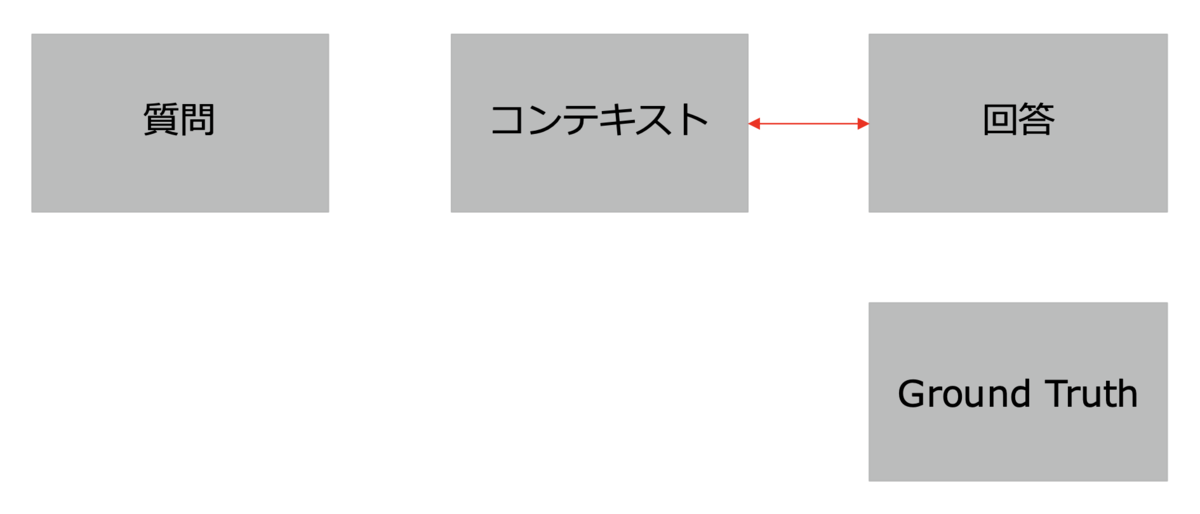
Faithfulness(忠実度) - Answer Relevancy(回答の関連性):回答が質問にどれだけ関連しているかを評価します。
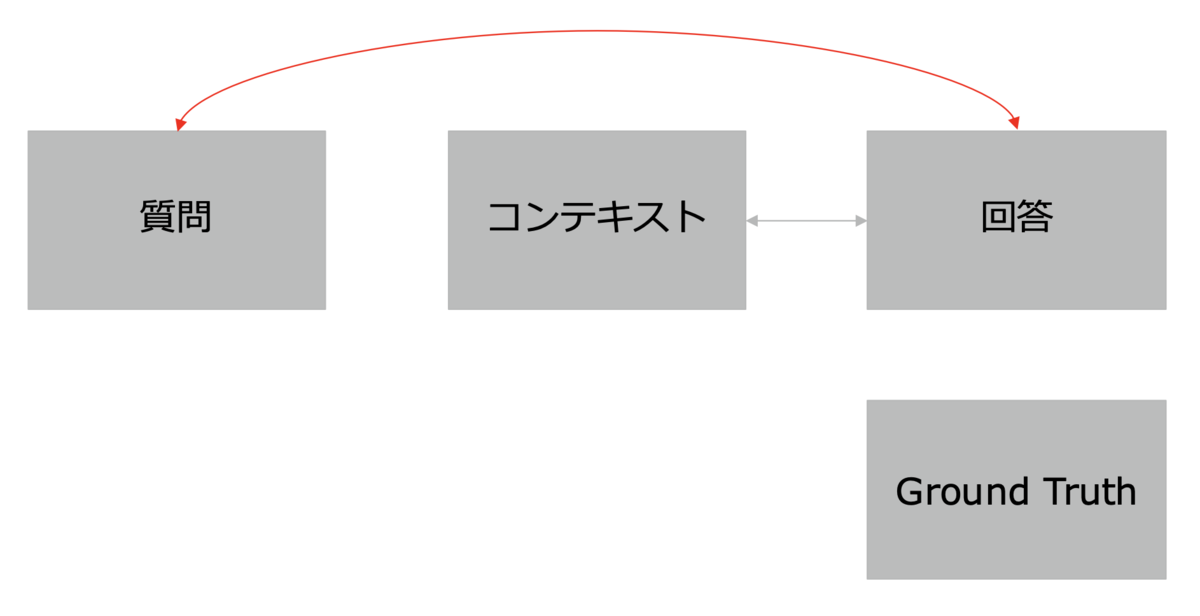
Answer Relevancy(回答の関連性) - Context Recall(コンテキストの再現性):検索結果として返された情報が多くの関連情報を含むかを測定します。
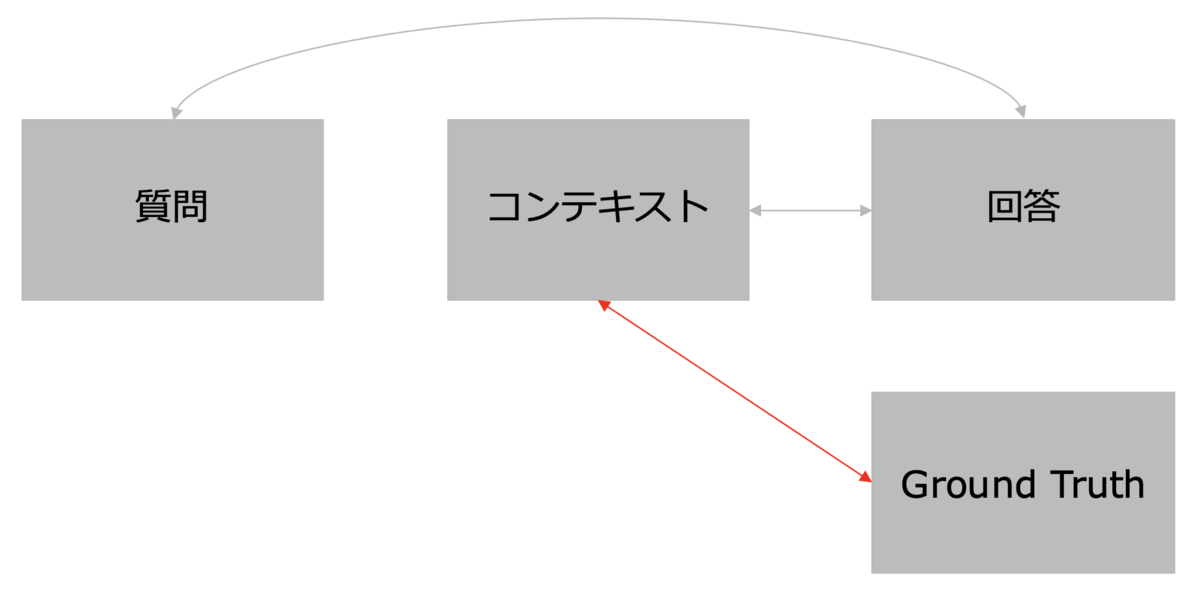
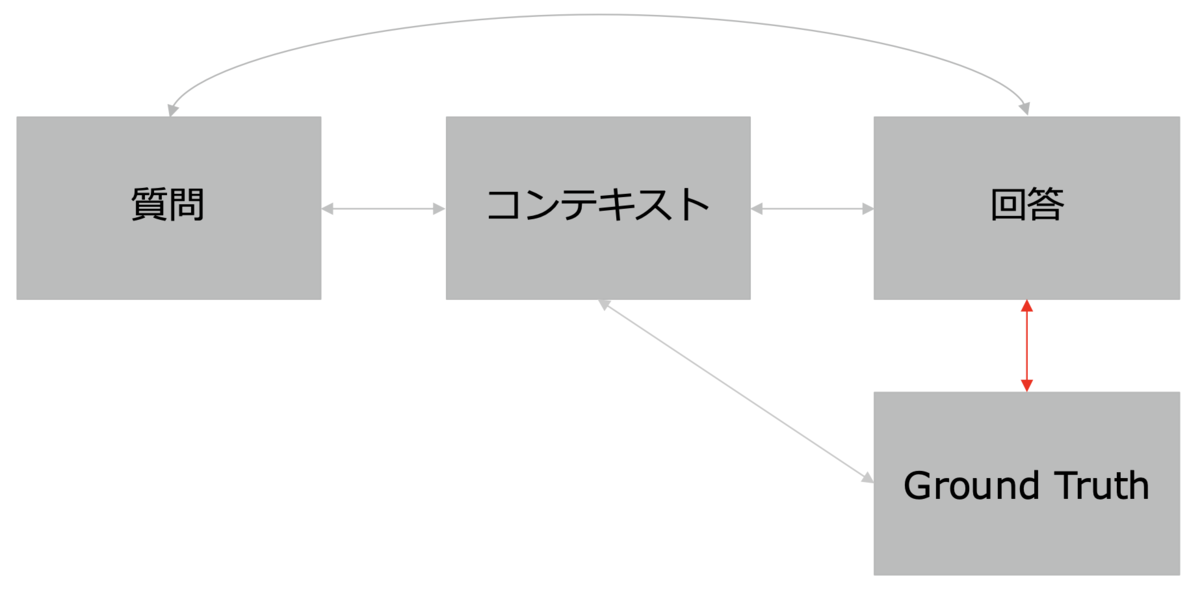
Context Recall(コンテキストの再現性) - Context Precision(コンテキストの精度):無駄なく関連情報を提供できているかを測定します。
[ 
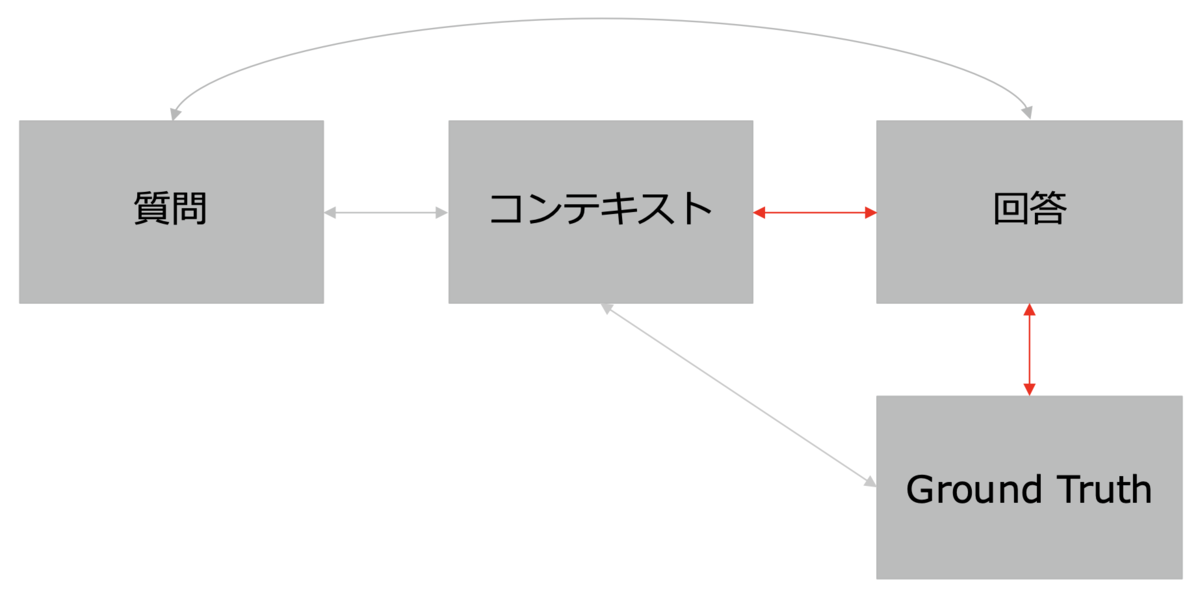
- Answer Semantic Similarity(回答の意味的類似性):生成された回答が期待される正答とどれだけ意味的に類似しているかを評価します。
[ 
- Answer Correctness(回答の正確性):生成された回答が誤りなく正確であるかを評価します。
[ 
検証内容と考察
評価結果には、Ragas評価モデルの「Gemini-1.5-Flash-001(※1)」が用いられており、各指標は以下のケースで計測されています(※2):
正しい回答が想定されるケース:
- 忠実度(Faithfulness): 1.0000
- 回答の関連性(Answer Relevancy): 0.6487
- コンテキストの精度(Context Precision): 1.0000
- コンテキストの再現性(Context Recall): 0.5652
- 回答の意味的類似性(Answer Semantic Similarity): 0.9188
- 回答の正確性(Answer Correctness): 0.2297
明らかに誤った回答が想定されるケース:
- 忠実度(Faithfulness): 1.0000
- 回答の関連性(Answer Relevancy): 0.3593
- コンテキストの精度(Context Precision): 0.0000
- コンテキストの再現性(Context Recall): 0.0000
- 回答の意味的類似性(Answer Semantic Similarity): 0.2427
- 回答の正確性(Answer Correctness): 0.0607
考察:正しい回答が想定されるケースでは、全体的に高いスコアが得られる傾向が見られましたが、内部処理の都合により一部の回答に誤差が含まれる場合もあります。そのため、バッチ実行による自動評価を行う際には、評価スコアの閾値設定やスコア分布の継続的な検証が必要です。今後、Ragasの改善動向をウォッチしつつ、一貫性のある基準の整備を進めていきます。
今後の展望
正式版リリース後、RAGシステムとLLM-as-a-Judgeの導入により社内文書検索機能は大きく進化しましたが、さらなる精度向上と業務効率化に向け、以下の点を重点的に改善していく予定です。
LLMフレンドリーな社内文書整備 現在、全社員がアクセス可能な文書は共有されるようになっていますが、社内には画像や非構造データが含まれる文書が多く存在します。このため、特に以下の対応が必要とされています:
- 古い社内ツールやサービスに関する文書の非公開化や更新。
- 画像が含まれるドキュメントへのアクセス改善。画像内の内容をテキストで説明するなどしてLLMによる理解をサポートする形式へと整理し、将来的にはAzure Document Intelligenceなどの技術も検討しています。
バッチ処理による評価の自動化 RAGシステムの精度維持のため、評価プロセスをバッチ処理で自動化する体制を構築する予定です。アドホック実行での自動評価は可能になっていますが、効率的な評価体制には、以下の追加対応が必要です:
- オンライン評価との連携:ユーザーからのフィードバックをGround Truthとして蓄積し、自動評価のためのデータベースを整備します。
- 評価結果の管理:評価指標を一貫して管理できるよう、Langfuseを使用したプロンプト管理やオブザーバビリティの強化を進める予定です。
まとめ
本記事では、社内文書検索機能の正式版リリースに至るまでの技術的な取り組みと、LLM-as-a-Judgeの導入について解説しました。ベータ版リリース時から多くの改善を経て、RAGシステムの精度が向上し、さらに自動評価体制を整えることで、今後も成長を続けることが期待されます。
正式版リリースにより、多くの社員が利用しやすい環境が整い、情報アクセスの効率化が進みました。今後もさらなる機能強化と課題解決に取り組み、業務効率化に寄与していく予定です。
注釈
※1: 自己中心バイアスの軽減を目的とし、異なる種類のLLMで評価を行う有効性が示されています。
参考:生成AIによる自動評価(LLM-as-a-Judge)のメリットと最新手法をご紹介
※2: Gemini-1.5-Flash-001モデルによるRagas評価には一部誤差が含まれる可能性があるため、実際のスコアは参考値として捉え、継続的な評価体制の整備を行っています。

梅本 誠也 Seiya Umemoto
デジタルテクノロジー統括部 生成系AIエンジニアリング部 生成系AIエンジニアリンググループ リードエンジニア
韓国で5年間正規留学し、その間に業務委託で機械学習とデータエンジニアリング方面の開発を経験。新卒でアプリケーションエンジニアとしてフロントエンド、バックエンド、インフラを幅広く経験。パーソルキャリア入社後はデータエンジニアとして、社内のデータ分析基盤の構築と運用保守を担当。一方で、生成系AIを用いたアプリケーション開発にも携わっている。
※2024年10月現在の情報です。