
はじめに
こんにちは。インフラ基盤統括部 プラットフォームグループの松原です。
プラットフォームグループでは、基幹データベースのコスト・パフォーマンス改善に取り組んでいます。
パーソルキャリアの基幹データベースは、Oracle Cloud Infrastracutre(OCI)上で、高性能データベースであるExadata Database Service on Dedicated Infrastracutre(ExaDB-D)を採用しています。
ここではOracle Dynamic Scaling Engineで利用して、ExaDB-Dのコストを削減した事例を紹介します。
ExaDB-D
ExaDB-Dは通常のOracleデータベースより高いパフォーマンスを発揮するデータベースです。
パブリック・クラウド上で利用できるサービスでありながら、専用のインフラストラクチャを利用できるのが特徴です。
基本の価格体系がCPU数+インフラストラクチャになっており、CPU数を変更することにより、柔軟にコストを調整できます。
CPU数は「オンライン」で、コンソール、APIを利用して、既存のワークロードに影響を与えずに変更することが可能です。
課題
ExaDB-Dの高いパフォーマンスを利用して、基幹システムを稼働していましたが、柔軟な価格体系のメリットを十分に活用できてはいませんでした。
一週間(月~日)のExaDB-Dの負荷とCPU数は下記のようになっています。
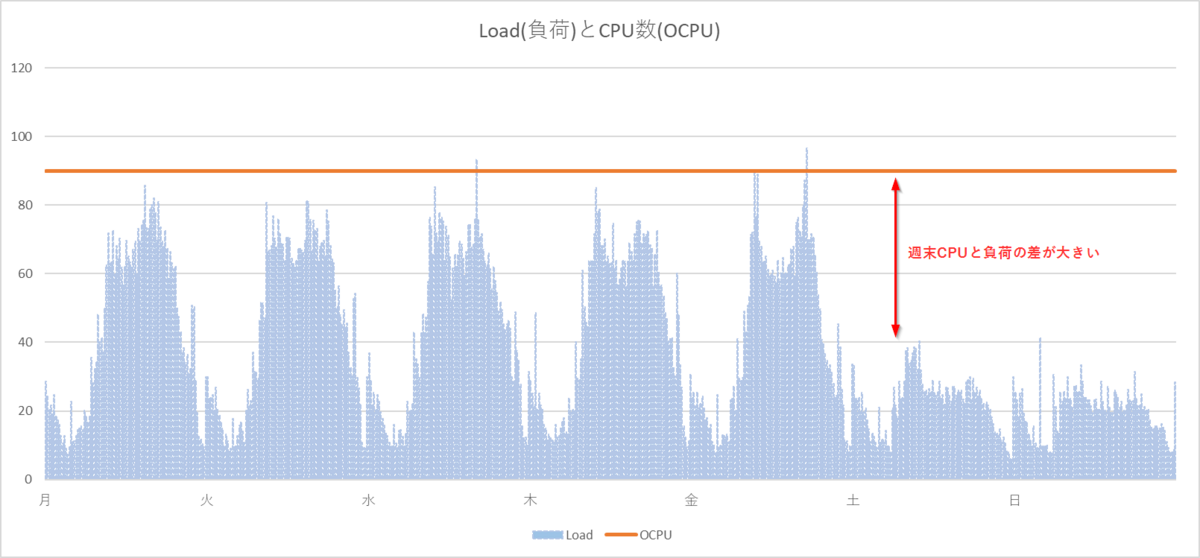
はっきりとわかるように、まず週末で負荷に対して、CPU数が余剰になっています。余剰になっている分は無駄なコストになっているといえます。
CPU数はオンラインで変更できるので、曜日・時間指定でCPU数を変更するバッチをしこんで、週末はCPU数を減らすようにしました。
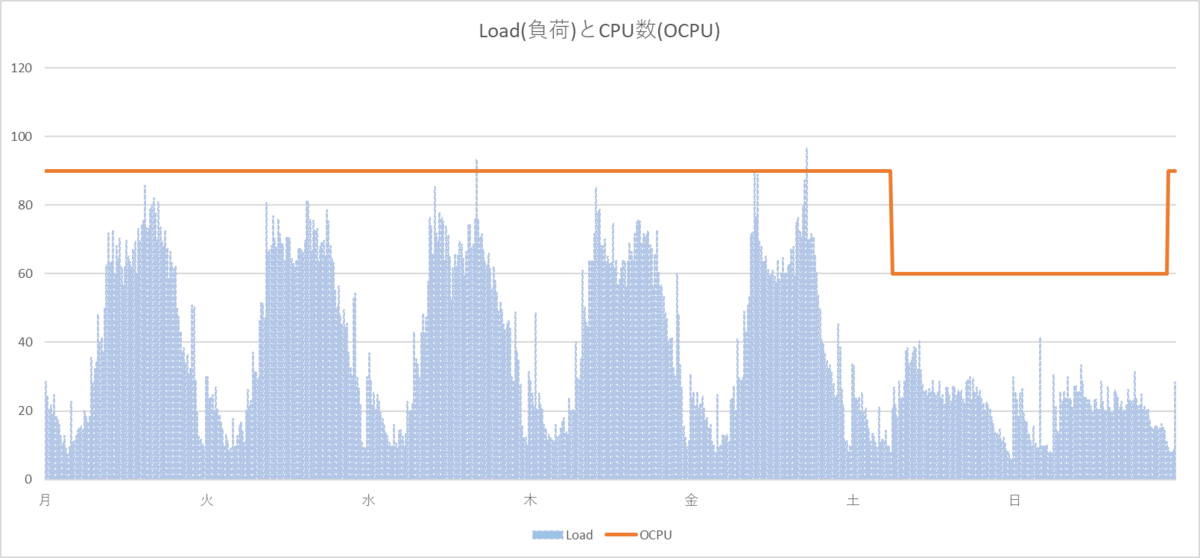
かなり減らすことができました。しかし、まだ減らせそうです。
なぜもっと減らせないのか?まだ課題として、以下を抱えていました。
- 曜日・時間指定なので、安全を重視したCPU数、時間指定になっている。この時間帯にもし突発的な負荷が発生した場合のリスクがある。
- 安全を重視するので、平日夜間のCPU数は調整できていない。
- 祝日など週末同様に負荷が低い日があるが、曜日・時間指定では対応できない。
平日日中帯のCPU数の運用にも課題がありました。
負荷に合わせて、1ケ月に一度CPU数を見直す運用をしていましたが、1月の間でも上旬、中旬、下旬で負荷の傾向が異なる、一律負荷に合わせたCPU数に固定することに苦慮していました。
Oracle Dynamic Scaling Engine
課題に対してやることは明確で、「ExaDB-Dの負荷(OS load average)を見て、動的にCPU数を調整する仕組みをつくる。」でした。
実際に1から仕組みを作るのは大変ですが、Oracleが動的なCPUスケーリングツールとして、Dynamic Scaling Engineを提供しています。 OracleサポートサイトからRPMパッケージをダウンロードして、インストールするだけで簡単に導入できます。
rpm -i dynamicscaling-2.0.1-29.el7.x86_64.rpm
構成を考える
Oracle Dynamic Scaling Engineを利用するにあたり、構成のパターンがいくつかあります。 ExaDB-D本体にOracle Dynamic Scaling Engineをインストールすることも検討しましたが、ExaDB-D本体への影響を最小化する目的で、ExaDB-Dと別のインスタンスにOracle Dynamic Scaling Engineをインストールして、負荷測定、CPUスケーリングはリモートから行う構成にしました。

OCI CLIを利用することで、リモートからでもCPU数スケーリングを行うことができます。
また便利なことに、リモートからExaDB-Dの負荷を計測するプラグインも、別途Oracleから提供されています。 こちらもRPMパッケージをインストールするだけで導入できます。
rpm -i dynamicscaling-plugin-1.0.1-11.el7.x86_64.rpm
実行してみる。
リモートでExaDB-Dの負荷を計測するプラグインを実行してみます。負荷が100~0の間の値で返ってきます。 ExaDB-Dは複数ノード上で動作しているので、複数のうち、負荷が高い方のノードの負荷を取得するように、loadtypeパラメータはmaxを指定します。平均値を取得する設定もできるので、DBのワークロード特性で調整することができます。
/opt/dynamicscaling-plugin/dynamicscaling-plugin.bin \ --ocicli \ --ociprofile XXXXXXXX \ --cloud-vm-cluster-id ocid1.cloudvmcluster.oc1.xxxxxxxxxxxxxxxxxxxxxxxxx \ --opcsshkey /root/.ssh/xxxxxxxxxxx \ --ip-type private \ --loadtype max \ --nosilent
成功すれば、標準出力に下記のように出力されます。
SUCCESS: 2023-06-20 15:57:30: Cluster max load is 52
指定したパラメータは別途設定ファイルに記載することで、実行時は省略できます。
プラグインが実行できたら、Dynamic Scaling Engine本体を起動します。 pluginのパラメータに動作確認したプラグインのファイルを設定します。
/opt/dynamicscaling/dynamicscaling.bin \ --ocicli \ --cloud-vm-cluster-id ocid1.cloudvmcluster.oc1.xxxxxxxxxxxxxxxxxxxxxxxxx \ --ociprofile XXXXXXXX \ --interval 600 \ --maxthreshold 90 \ --minthreshold 60 \ --maxocpu 100 \ --minocpu 40 \ --ocpuup 20 --ocpudown 10 --shape Exadata.X8M \ --plugin /opt/dynamicscaling-plugin/dynamicscaling-plugin_wrapper.sh
これで対象のExaDBの負荷を計測して、自動でCPU数をスケールするようになります。すごく簡単です。
(実際に本番運用するときは、systemdでサービス登録して利用しています。)
仕様とパラメータ
起動するのは簡単ですが、本番運用前に、実際にエラーが発生しないか、パラメータが期待通りに動くか、検証環境で確認します。
Dynamic Scaling Engineの機能は主に下記のとおりです。パラメータを変えて、機能通りに動くか検証していきます。
- CPU負荷によるCPUスケーリングの自動実行
- CPU負荷に対する上限および下限の閾値、監視間隔を定義(maxthreshold, minthreshold, interval)
- 設定する最小または最大CPU数まで負荷に応じて自動的に増減(maxocpu, minocpu)
- スケールアップ、スケールダウンするときのCPU数幅を定義(ocpuup, ocpudown)
- スケールダウン遅延。負荷が低下したときにスケールアップ後から2時間はスケールダウンしない。
(スケールアップ、スケールダウンの操作が頻繁に行わるのは好ましくありません。そのため、一度スケールアップした後は、2時間はスケールダウンしない仕組みが採用されています。 この2時間という時間は変更できません。)
- スケジュールによるCPUスケーリングの自動実行
- 曜日と時間を指定
- 指定しない時間はCPU負荷によるCPUスケーリングの自動実行
パラメータが期待通りに動くことを確認できたら、パラメータの値を検討します。
本番相当のワークロードを検証環境で再現するのは難しいので、机上で計算をしました。
AWRデータのビューであるDBA_HIST_SYSMETRIC_SUMMARYからOS Loadの平均、標準偏差を参照できるので、そのデータを活用します。
どのパラメータでどの程度コスト削減できるかExcelでシュミレーションします。

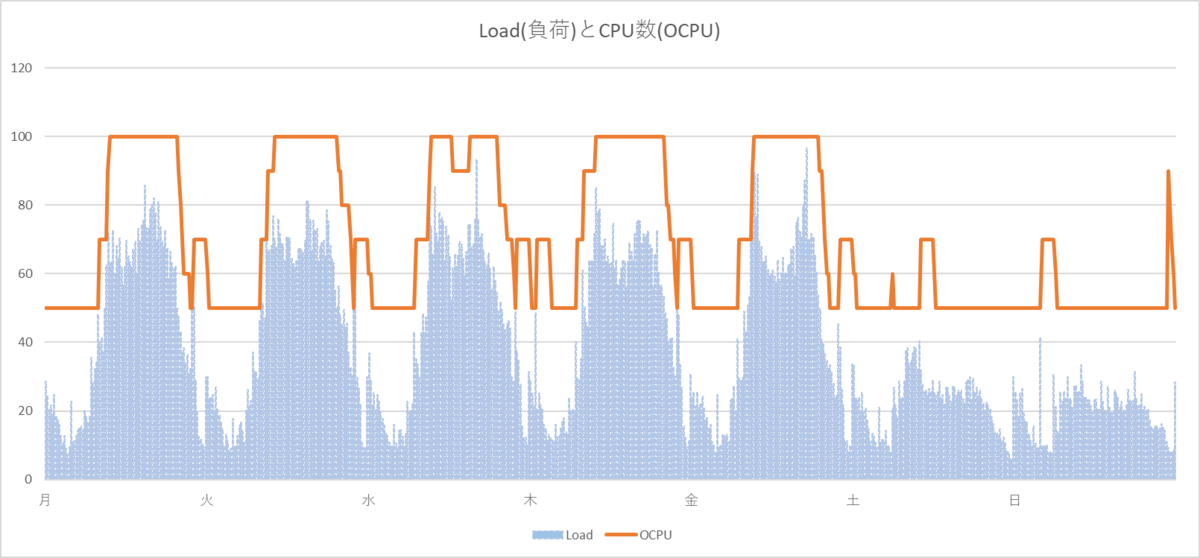
安全にパラメータを指定しても、だいたい15%はCPUコスト削減できそうな見込みがわかったので、試算したパラメータで本番運用をしていきます。
本番導入結果
ある1日のCPU数とLoad Averageの状態です。
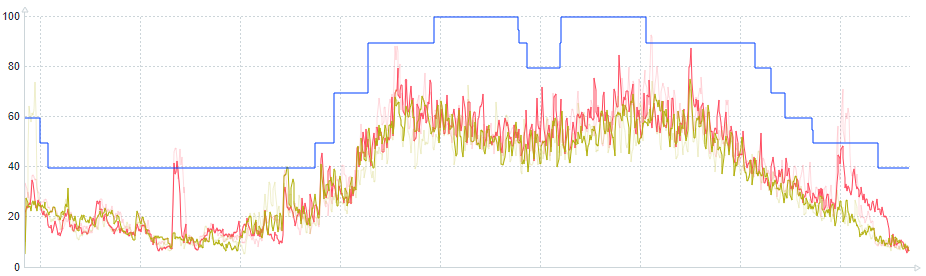
本番運用した結果、試算したパラメータで想定していたコスト削減効果が得られました。
CPU数も負荷に則して、無駄なくCPU数を減らすことができています。
CPU数を減らすだけでなく、負荷が高いときは通常よりCPU数を増やすこともできるので、負荷を見て、CPU数を手動で調整する運用から解放されました。
本番運用でわかった課題
負荷による自動スケーリングでの一般的な課題ですが、突発的な負荷上昇にスケール機能が対応できるかというリスクがあります。 特に始業開始時間近辺は、データベースの負荷が急に上昇することがあるので、スケールアップが間に合っているか、常に状況を確認しています。
現状では、時間起動のバッチで、CPU数を指定した値まで引き上げる運用をしています。
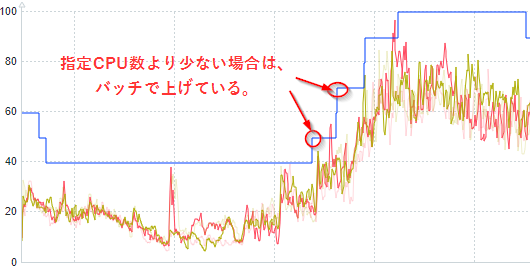
Dynamic Scaling Engineにはスケジュール指定で、例えば平日8時台は、CPU数を指定した値に固定するという機能もあります。 しかし固定にしている時間は、自動スケーリングがOFFになり、もしその時間帯に負荷が上昇した場合のリスクがあるので、スケジュール指定の機能は採用しませんでした。
特定時間帯に想定される負荷上昇に対して、うまくウォーミングするのが今後の課題になっています。
まとめ
負荷に対するCPU数の自動スケーリング機能を1から作りこむと、エラー処理の検討など、それなりに手間がかかかります。 Dynamic Scaling Engineを利用すれば、インストールして、あとはパラメータを調整するだけで、簡単に導入できます。
導入した後は、CPU数をスケジュール時間指定で決め打ちで調整するよりも、負荷が高くなれば自動でスケーリングしてくれるので、安心感も高いです。
Dynamic Scaling Engineは、他社で本番運用している事例を聞けず、期待通りに動くか検証に時間をかけましたが、検証でも本番運用でも問題なく稼働することができています。
ExaDB-Dを使用しているのであれば、ぜひ試してみてください。

松原 諭 Satoshi Matsubara
インフラ基盤統括部 システム共通BITA部 プラットフォームグループ リードエンジニア
2023年1月にパーソルキャリアに中途入社。プラットフォームグループのDB担当として、基幹ExaDBの改善、安定化に従事。
※2024年1月現在の情報です。