

みなさん、こんにちは。dodaのサイト開発をしているエンジニアの佐藤です。
今回、dodaサイトで「KVS with Debezium導入」に挑戦し、さまざまな知見を得られたので、その経験を記事にしました。
この記事のサマリー
- Debeziumを本番環境へ適用することに挑戦
- 本番適用するも問題が発生
- Debeziumを断念し、独自のデータ転送を実装
- 結果的に知見を得ながらKVS導入を達成!
<挑戦で得られた知見>
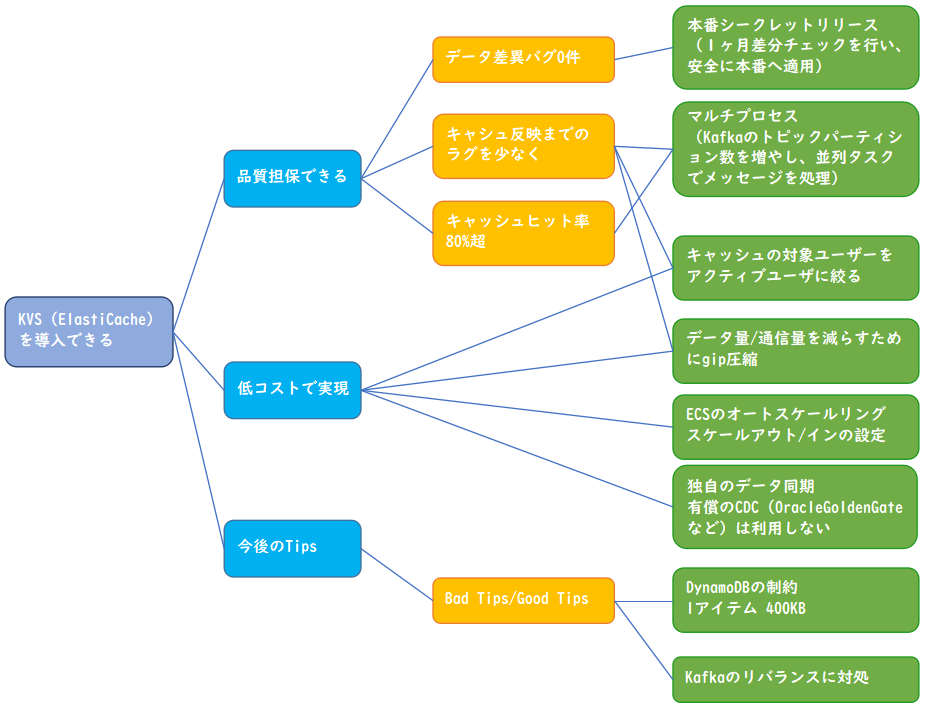
なぜKVSを導入したのか?
数億のレコード数を持つテーブルからSQL発行でデータ取得していた機能に対し、以下2つの目的をもってKVSを導入しました。
- 画面表示の高速化
- アクセス頻度の高いテーブル(RDB内)に対する負荷軽減
対象画面について
イメージが湧きやすいようにKVS導入の対象画面について、簡単に説明します。
「企業からのオファー」という画面で、会員様向けに企業側からのオファーメッセージを一覧形式で表示する画面です。

Debezium採用時のアーキテクチャ
RDBからDynamoDBへどのようにデータを転送するか?については、CDC(Change Data Capture)の仕組みを採用することにしました。
CDCの仕組みを上手く適用できた場合、今後のサービス拡張および改善に有効な手段となり得るという期待もありました。
対象画面は、ログインしているユーザーのデータのみを表示する仕様であるため、ユーザーIDをキーとしてデータ格納ができるKVSの導入は適切であると考えました。
そして、以下の理由から「Amazon DynamoDB」を採用することにしました。
- フルマネージドなサーバーレスサービス(運用が楽)
- 数ミリ秒レベルの一貫したレイテンシ性能
- テーブルで管理できるアイテム数(レコード数)は無制限
- ユーザーIDを条件としたシンプルなクエリで良い
- セカンダリインデックスによる絞り込み条件/ソート条件の追加も可能
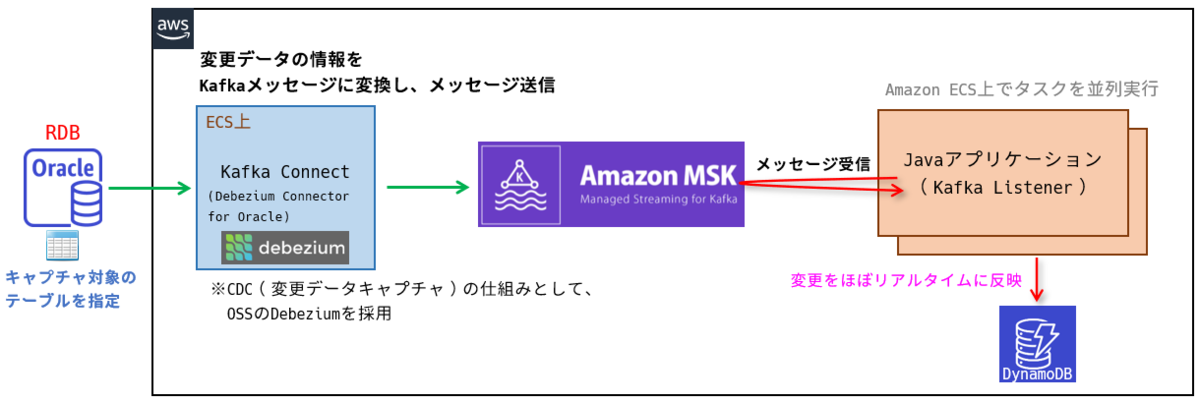
いざ本番環境へリリースしてみると
CDCを採用したアーキテクチャをテスト環境に適用し、パフォーマンステストも順調に完了しました。
パフォーマンステストでは、キャプチャ対象のテーブルに対し、10万件のUPDATEを実行し、変更データが遅延なくKafkaまでメッセージとして届くことを確認しました。
(遅延も平均数秒で、Max15秒程度でした。)
しかし、いざ本番環境へ適用してみると、問題が発覚。
そう上手く行きませんでした。。。
具体的な事象としては、キャプチャ対象のテーブルで登録/更新が行われたあと、Kafkaへメッセージが送信されるまでの遅延(ラグ)が最大で12時間を超えてしまいました。
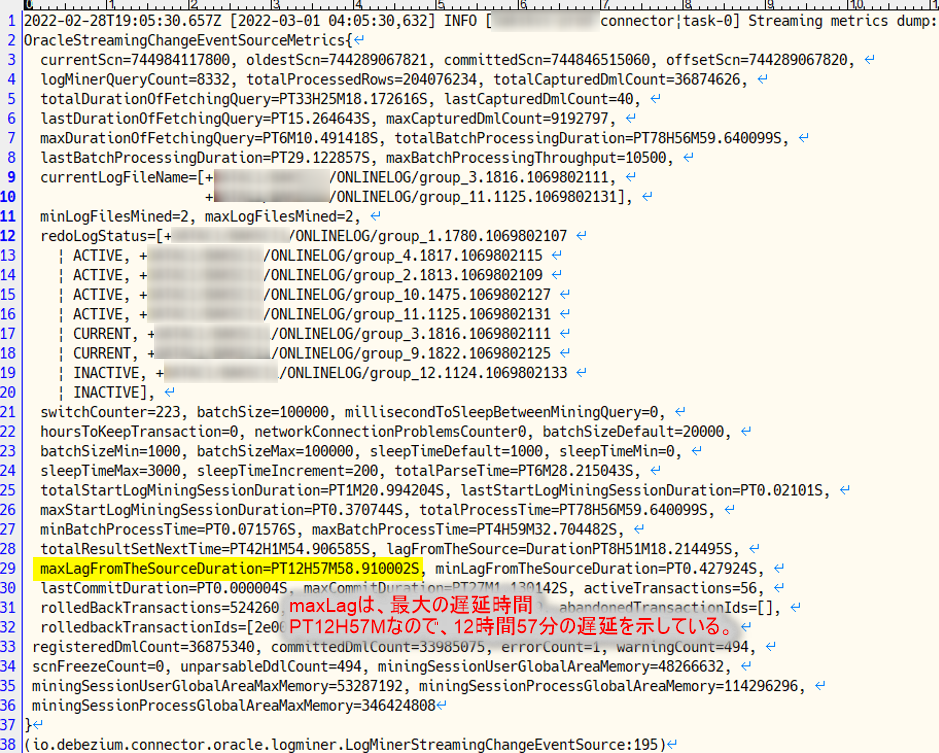
問題解決のため、debeziumコミュティのメーリングリストを通じてサポートいただきましたが、結果としては解決できませんでした。
原因は以下と考えています。
- debeziumは、内部処理としてOracleのLogMiner経由でREDOログを参照し、キャプチャ対象テーブルの変更情報を取得している
- LogMinerは、Oracleの標準ツールだが、CDC向けに提供されている機能ではない
- 本番環境のデータベースは全体のトランザクション量が多く、REDOログ・ファイルのサイズが大きい(REDOログの変更量は30GB/時間を超える)ため、性能限界を超えてしまった
AWS DMS の説明サイトにも「REDOログの変更量が30GB/時間を超える場合は、Oracle LogMiner を使用するより Binary Reader を使用する方が、CDCのパフォーマンスは通常ははるかに高くなります。」と記載があるため、LogMinerには性能限界があると思われます。
Debezium自体は、とても良いソフトウェアですが、適用する場所は慎重に選んで頂きたいです。
ちなみにテスト環境で、パフォーマンス問題を検知できなかったのは、テスト環境のトランザクション量が本番環境と比較して非常に少なかったためです。
アーキテクチャを再設計することに!
Oracle GoldenGateなどの有償製品も検討しましたが、コストおよびパフォーマンス問題を懸念し、CDCの採用は断念しました。
そして、「画面表示する可能性のあるユーザーのデータを先回りして、KVSに登録しておく」という方式をとることにしました。
画面表示する可能性のあるユーザーは、ログイン後のユーザーであり、ログイン認証を通過した直後、RDBに存在するこのユーザーのオファーデータをKVSへキャッシュする設計に変更しています。
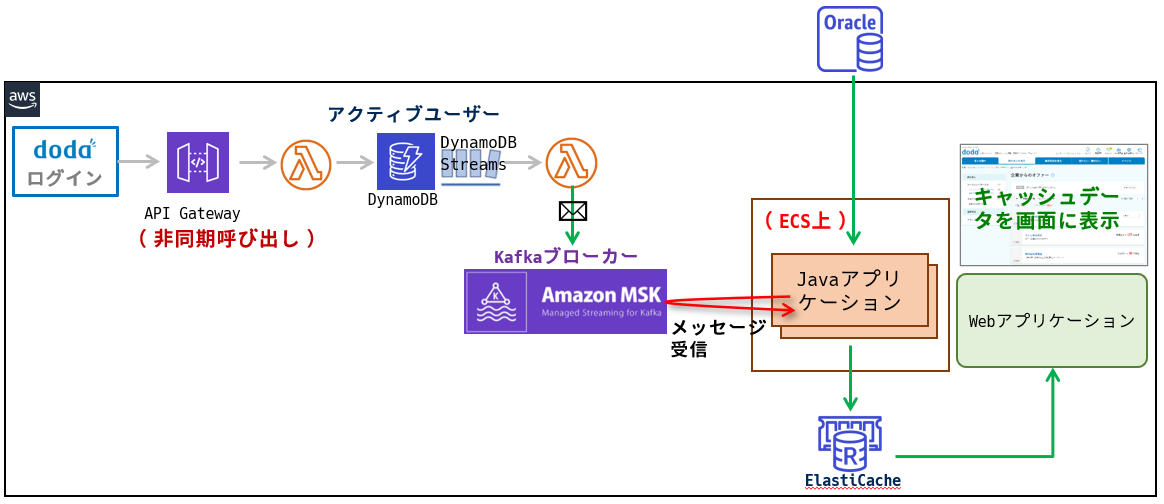
【再設計のポイント】
- 既存のログイン認証処理に影響を与えないよう非同期でアクティブユーザーを登録するAPIを追加
- アクティブユーザーはDynamoDBで管理し、テーブルのトリガー経由でKafkaへデータのキャシュを指示するメッセージを送信
- Kafkaのトピックはパーティション数を24に設定し、ログインが集中する時間帯でもECSタスクを増やしながらキャッシュ待ちが発生しない設計に
- アクティブユーザーを登録する機能とオファーデータをキャッシュする機能を分離し、Kafka経由で連携することで、オファーデータ以外にも対応できる仕組みに
再設計したアーキテクチャで苦労したこと
- 再設計当初、データのキャッシュ先は、ElastiCacheではなくDynamoDBであったが、データ件数の多いユーザー(5000件を超える)の場合、1件ごとにテーブルへ登録する実装では時間が掛かり過ぎてしまった
- 更に、batchWriteItem(25件ごとのバルクインサート)を使って実装したが、大きな改善には至らなかった
- そこで、1ユーザー分の全データをjson形式に変換し、1レコード(DynamoDBの場合、1アイテム)で登録するように実装を変更したが、DynamoDBのサイズ制約(1アイテム 400KB)を超えてしまい、DynamoDB→ElastiCacheへ変更した(Redisの場合、上限512MBなので問題なし)
- また、1ユーザー分のjsonデータをElastiCacheへ格納する前にgzip圧縮を実行
再び本番環境へリリース!
本番環境へリリース後、約2週間は、正常に稼働していました。
キャッシュヒット率も目標としていた80%を超えている状態でした。
(キャッシュヒット率は、ElastiCacheのメトリクスの1つ)

しかし、突然、キャッシュヒット率が低下しました。
Kafkaコンシューマのリバランスが繰り返し実行され、メッセージが消費されていなかったことが原因でした。
リバランスとは、トピックのパーティションに対するコンシューマの再割当てのことで、アーキテクチャ図上だとJavaアプリケーション(複数のECSタスク)がコンシューマに相当します。
どのパーティションをどのコンシューマが担当するか?は、一度決まったあと、再割り当てすることなくそのままのほうが効率が良いのですが、コンシューマの数が変わったり、あるコンシューマの処理時間が長くなったりすると、リバランスが発生します。
対策としては、リバランスの抑止に効果のありそうなコンシューマ・プロパティの設定値を変更しました。
# コンシューマがメッセージの処理を継続していることを確認する間隔(初期値の倍を設定)
max.poll.interval.ms
上記の設定変更後は、一度もリバランス問題は発生していません。
ECSのオートスケーリング設定について
オートスケーリングを設定するにあたり、Kafkaに滞留している「消費待ちのメッセージ数」に着目しました。
一般的には、ECSタスクのCPU使用率などのメトリクスをもとにオートスケーリング設定しますが、CPU使用率の変化があまりなかったため(1タスクあたり、2スレッドでメッセージをリッスンする設定にしたため)です。
Kafkaのパーティション数は24で固定し、消費待ちのメッセージ数に応じて、6タスクから12タスクに変動するよう設定しました。
6タスクの場合: 6*2スレッド = 12コンシューマ
12タスクの場合: 12:2スレッド = 24コンシューマ
(注意)パーティション数よりもコンシューマ数が多くなる設定は意味がないです。コンシューマがアイドル状態になってしまいます。
消費待ちのメッセージ数は、Amazon MSK(Kafka)に SumOffsetlag というメトリクスがありましたので、これを使うことにしました。
消費待ちのメッセージ数が10未満: 6タスク
消費待ちのメッセージ数が10以上: 12タスク

キャッシュしたデータは本当に正しい?の検証
テストは十分に行いましたが、データパターンや画面表示の絞り込み条件、ソート条件などすべてを網羅的に確認できないため、約1ヶ月、本番環境でデータ検証を行いました。
データ検証の内容は以下の通りです。
- 対象画面を表示するリクエストのうち0.5%だけ、「RDBからデータ取得する処理」と「キャッシュからデータ取得する処理」の両方を実行
- プログラムにて表示データ(並び順も含め)に差異がないか?チェックし、差異があった場合は、その内容をログに出力
- ログは、Dodadogで日々監視し、差異発生 → 原因究明 → 対処 を実施
この検証によって、いくつかのバグを修正することができ、また、考慮できていなかった事象(次の「ElastiCacheのキャッシュ有効期間」に繋がる話です。)によるデータ差異も検知することができました。
ElastiCacheのキャッシュ有効期間
- 有効期間(TTL)は、現在5分に設定
- 頻繁に変更が入るようなデータではないため、長い期間を設定したかったが、日中に数回実行されるバッチ処理によって、新しいデータが追加されるため、最終的にこの設定値に落ち着いた
テスト環境について
テスト環境は、システムテストを含め複数の環境が存在します。
環境ごとに「Amazon MSK」「Elasticache」を用意するとAWSのランニングコストが増えてしまうため、以下の工夫をしています。
まず、MSKは1つ用意し、テスト環境ごとに「Kafkaトピック名」を分けて使っています。
トピック名は、ECSタスク定義の環境変数で設定できるようJavaアプリケーション側も対応しています。
また、Elasticacheは、環境名を「キーの接頭語」に付加(例:st:offer:1001294759)して、環境を分けています。
MSKもElasticacheも、一時停止することができないので、このようなコスト削減を行っています。
最後に
KVS導入の2つの目的に対し、結果どうだったのか?ですが、1つ目の「画面表示の高速化」については、概ね改善できました。
特に解析済みのSQLがRDB上にない状態での速度比較は顕著でした。
2つ目の「テーブルへのアクセス負荷軽減」ですが、これは、ほぼ変わらずの状況です。
理由は、最終的に設定した「キャッシュの有効期間」が5分と短いためです。
キャッシュヒット率が90%前後であるため、キャッシュのデータを有効に参照できていますが、5分を超えると再キャッシュの処理が走り、RDBからデータを再取得する処理も実行され、アクセス負荷が軽減されませんでした。
これを改善するためには、バッチ処理で新たに追加されたデータをそのタイミングでキャッシュに載せるようにし、キャッシュの有効期間を長くすれば良いと考えています。
今後は、上記の課題を解決し、この仕組みを他領域へ活用していきたいです。
もしも、このような開発に興味を持っていただけたエンジニアの方がいらっしゃいましたら、ぜひジョインして欲しいです!

佐藤 政美 Masami Sato
プロダクト開発統括部 エンジニアリング部 dodaエンジニアリンググループ シニアエンジニア
SIer、会計パッケージベンダーを経て、2020年7月にパーソルキャリアに入社。入社後は、dodaサイト開発に携わりつつ、AWSを活用した新たな開発に取り組んでいる。
※2022年11月現在の情報です。