

はじめに
こんにちは。クライアントプロダクト本部テクノロジー統括部の熊切です。 普段はdodaの膨大なマーケットデータを用いて採用活動を支援するHR forecasterの開発を行っております。 https://hr-forecaster.jp/
特にGoogle Cloud・Terraformを中心としたサービス全体の基盤構築に携わっています。
今回はAIエージェントを活用した業務効率化の可能性を探ったお話ができればと思います。
背景
パーソルキャリアではdodaを中心とした多岐にわたるサービスを展開しております。 全サービスにおいて、お客様に安心してご利用いただけるよう全社的にデータ仕様・コンプライアンスチェックを徹底して実施しております。
特に個人情報・重要情報を多く扱うシステムではより強固なセキュリティ対策が必要になります。その上で日々データは変化していくため、現状サービスがどのくらいの規模の機密情報を取り扱っているのかを知ることは非常に重要です。
またデータ量だけでなく、サービスで扱うデータ項目も時間とともに変化していきます。これらはリアルタイムで同期されていることが理想ですが、現状では下記のような課題があります。
- DBスキーマと機密情報の対応表がスプレッドシートで管理され、ドキュメントのメンテナンスコストが高い
- 現状のDBスキーマとスプレッドシートのデータ項目が合致しているか都度調査が必要
これらは毎回の調査において、コストが高く業務として改善の余地がありました。
目的
上記のような課題解決のため、以下を達成できるような構成の検討を行いました。
- DBスキーマのデータ項目を自動で抽出可能にする
- データ項目に対してラベリングを行い、集計したい対象を簡単に検索可能にする
これらを解決するための具体的な手法としてデータカタログの利用を検討しました。 加えて昨今のAIエージェントの有効性を探るため、上記整備後AIエージェントを構築しました。
データカタログ検証
検証前準備
現在Google Cloudをメインで使用しており、データはCloud SQL上で管理されています。 今回は実運用に向けた構成ではなく、あくまで有効性検証に留まるためCloud SQL上にデモ用データを作成しました。 データ構成は以下の通りになります。今回はECサイトを仮定し個人ユーザーと注文に関する構成にしました。

Dataplex Universal Catalog
Dataplex Universal CatalogはGoogle Cloudが提供するデータカタログサービスです。
Dataplex Universal CatalogはGoogle Cloud上に存在する組織内のあらゆるデータを一元管理・検索できる統合カタログプラットフォームです。
https://cloud.google.com/dataplex?hl=ja
データウェアハウス・バケットなどに格納されているメタ情報を一元管理することが、主な使用用途になりますが、今回は拡張しCloud SQLに対して適用しました。
エントリ・アスペクトタイプ・アスペクト
エントリ・アスペクトはDataplex Universal Catalogにおける用語になります。
- エントリ:管理対象となるデータ資産そのもの
- アスペクトタイプ:メタデータのひな形。データ型や構造を定義したもの
- アスペクト:エントリに紐づけられた具体的なメタデータ情報
Cloud SQLに対する有効化
Dataplex Universal CatalogはBigQueryなどでは自動でメタデータを抽出してくれますが、Cloud SQLでは明示的に有効化する必要があります。 下記公式ドキュメントを参考に作成したCloud SQLに対して実行しました。なお反映までにある程度時間がかかるので注意が必要です。 https://docs.cloud.google.com/sql/docs/postgres/dataplex-catalog-integration?hl=ja
メタデータ設計・付与
上記ではDataplex Universal CatalogがCloud SQLのスキーマが読み取れるようになりました。 目的達成のためには、手動で各データ項目に対するメタデータの付与が必要になります。 データ項目に対する機密情報であるかの判断は、社内で規定されておりその規定通りに付与する必要があります。
今回は規定を模擬してアスペクトタイプInformation Asset Registerを設計しました。
- 機密性:高 / 中 / 低
- 企業秘密分類:取引先情報、個人顧客情報、従業員情報、その他
- 企業秘密内容:"自由記述"
作成したアスペクトタイプに合致するように各カラムに対して、アスペクトを付与しました。
今回であればusersテーブルに存在する氏名、電話番号、メールアドレスが該当します。
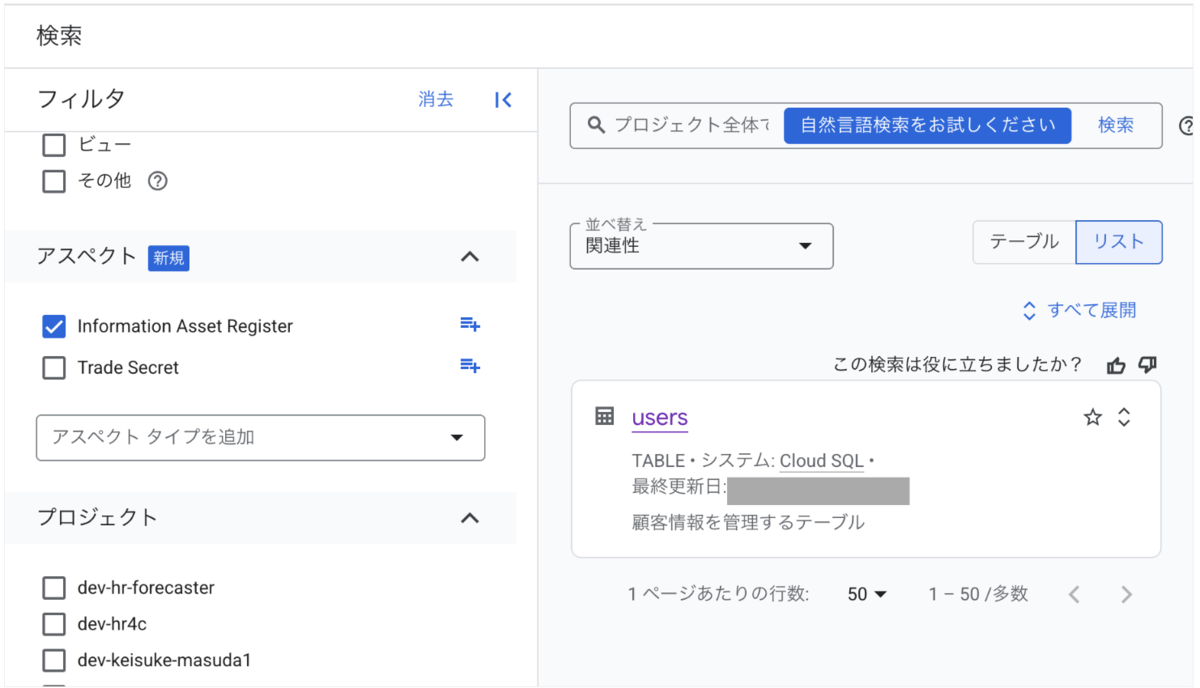
結果
下記のように該当する値を検索することで、該当テーブルを一覧化してくれました。 これによりスキーマ情報をスプレッドシートで管理することなく対応可能になりました。
なおデータ件数については下記SQL(PostgreSQL)にて取得可能です。
SELECT relname, n_live_tup FROM pg_stat_user_tables WHERE schemaname='スキーマ名' AND relname IN ('users');
AIエージェント検証
上記にて半分の目的を達成できたので、続いてAIエージェントの検証を実施しました。 実のところ今回の要件ではSQLのみで対応可能なのですが、データ拡張が大規模に及んだ時を想定して構築しました。
AIエージェント構成
今回はGoogleのADK ( Agent Development Kit )とMCP toolbox for databasesを用いて構築しました。
- https://google.github.io/adk-docs/
- https://codelabs.developers.google.com/travel-agent-mcp-toolbox-adk?hl=ja#0

今回は向学も兼ねてマルチエージェントで構成しました。 実行させたい処理を一連の流れとしてAgentを構成することで、意図しない処理を防ぐことを目的としています。 流れとしては以下のようになります。
- そもそもどのようなアスペクトが存在するのか取得
- 利用者が検索したいエントリを抽出
- そのエントリに含まれるレコード数を調査
結果
結果としては下記画像のようになりました。 自動でアスペクトタイプを検知しレコード件数を取得することができました。

今後の展望
AIエージェントの導入により、自動的に社内コンプライアンス要件に沿ったデータ件数を取得することができました。 実際に導入するまでには下記のような更なる検討が必要になります。
- スキーマ更新が行われた際、手動でメタデータを付与する必要がある
- AIエージェントの粒度が細かすぎる
1点目については、もともと解消したかったスプレッドシート管理からの脱却とスキーマ同期まではできたのですが、スキーマ更新が行われた際には現状手動でメタデータを付与する必要があります。 完全な自動化のためにはイベント型のデータ付与の機構が必要になります。
2点目については、現状のAIエージェント構成ではかなりタスクを固定化してしまっているため柔軟なタスクができないのが課題点としてあります。そのためもう少し粒度を調整し、AIエージェントに対する指示の整備が必要になります。
まとめ
今回は業務効率化のため、機密データ判断システムを構築しました。 Dataplex Universal Catalog・AIエージェントを導入することで、これまで抱えていたドキュメント同期・調査効率を向上できる可能性を示唆しました。 まだシステムとしてブラッシュアップする余地がありますが、導入によりこれまでと比較し柔軟かつ効率的な対応が可能になりそうです。

熊切 俊夫 Toshio Kumakiri
クライアントプロダクト本部テクノロジー統括プロダクト開発1部
2023年4月新卒でパーソルキャリアに入社。現在はHR forecasterのインフラを中心としたサービス基盤構築に従事。
※2025年12月現在の情報です。