

求人情報を提供する企業は、全国求人情報協会が定める基準に則り、求人広告・求人票の掲載基準を遵守しなければなりません。パーソルキャリアでは、法人営業や求人制作チームが求人票を作成した後に、これらの掲載基準を確認する求人審査部門があります。過剰な表現、根拠のない数字、表記揺れなど、掲載基準に抵触しそうな表現がある場合には、審査部門から指摘が入り、原稿修正を繰り替していますが、手戻りが多く発生していることが課題でした。そこで立ち上がったのは、AI活用によってヒューマンエラーや制作の際のサポートを実現している「求人審査AIプロジェクト」。本プロジェクトは、デジタルテクノロジー統括部のビジネス、エンジニア、アナリティクスが中心となって、この求人審査に伴う事業側の課題を解決していきました。いくつもの部署をまたぎ、多くの関係者が絡むプロジェクトならではの苦労と仕事の醍醐味について同部署の北島、大前、髙橋に話をきいてきました。(※大前は当日オンラインから参加しました。)
すべての求人を目視で確認する限界――審査部門が抱える課題
――まずは、求人審査AIプロジェクトの概要からお聞かせください。
北島:dodaに掲載されている求人広告・求人票の表現は、全国求人情報協会に定められた基準に従って、パーソルキャリア独自に定めたルールが存在します。さらに当社では、求人票だけではなくスカウトメールなどでも同様のルールを引いていますが、こちらのチェックは外部委託しています。

チェックする求人件数は月に数千件に上り、チェック項目は法改正などに伴い、随時アップデートされていきます。それをすべて審査部門の人の目で間違いなく確認してきましたが、コストをかけずにミスなく遂行することは相当難易度の高いことです。また外部委託費も膨らんでいたことから、費用削減の目的もあり、AIの導入が決定。効率化を図ったのが、今回の求人審査AIプロジェクトとなります。
そもそものきっかけは、僕がパーソルキャリアに入社後、事業部門の方からのヒアリングを重ねながら、業務改善のアイデアを練っていたときのこと。業務内容は複雑ですが、審査部門がきちんとルールを作り、法改正に伴いしばしば変更はあるものの「このキーワードはNG」といったように、審査基準も比較的明確になっていました。そうであるなら、機械学習を活用して判定ができるのではないかと考えたのが最初です。
その後、ルールや表現の一例をとってみて、本当にそれが可能なのかを検証。アナリティクスを担当する大前さんに「この文章からこの表現を抽出することは可能か」と相談すると、BERTを使えばできそうと話があり、そこから本格的にプロジェクトがスタートしました。
――仕事を選択する求職者にミスリードが無いようにチェックが必要なんですね…。BERTという選択肢はそもそも考えていたんですか?
大前:北島さんから「こういうことがしたい」と言われ、そこからやり方を考え始めました。ただ、ちょうどその話が来るちょっと前からチームでBERTの調査はしていたのですね。
今回の案件では、キーワードを抽出する作業が中心になるので、BERTの中にある質問に対して答えを返するタスクがあったので、それを応用できるのではと思い、すぐに検証を始めました。
北島:もっとも厄介なのが、求人票の中で自由記述となっている職種名やタイトル、仕事内容です。その中からNG表現を探して判定する作業はとても骨が折れます。BERTで学習させるためには、文章の中から、それだけたくさんあるNG項目に含まれる表現を見つけるテストデータを作らなければなりません。それは外部の会社に依頼しました。
――例えば「業界1位」というワードが禁止だった場合、近しい単語である「業界トップ」というワードも引っ張れるのでしょうか。
※編集部補足:その企業が「業界1位」という公式なデータがない限り、1位という表現は根拠のないランクになるため、求職者に誤解を招いてしまう可能性があるため、NGとしています。
北島:それは可能です。類似のワードをAIに学習させて、それをBERTに組み込んでおけば、新しい言葉が出てきたときに類似表現だと判断します。NGワードにマッチングさせるだけであればAIを使わなくても抽出できますが、営業担当ごとに、さまざまな表現を使って記述しているので、類似表現が増えていく可能性があります。またルールや法律が変更されることによって、追加でNGワードも増えていきます。きちんと学習させて常にマッチデータを作っておく必要があるので、AIを使うという発想が生まれました。
大前:そうですね。単純に10個のNGワードだけを抽出するとなれば、ルールだけで抽出することが可能ですが、似たような意味でも様々な表現があるので、ルールを作るだけでは、判定精度が低下するばかりです。

――1対1のルールを作るだけではなく、ルール項目が増えても、精度が上がるようにしなければならないんですね。AIが学習するためのテストデータというのは、どのようなものなのでしょうか。
北島:求人票に記載される「職種名」や「仕事内容」の自由記述部分が対象範囲になるので、Excelにアウトプットします。その右側に、自由記述の中に含まれている優位性表記(業界1位など)を抽出したものがテストデータになります。それを我々がチェックし、最終的には大前さんに渡してBERTに学習させましたけど、かなりの数がありましたね。これは今回のプロジェクトにおいて、もっとも重要な準備のひとつ。機械学習を実用化するためにはテストデータ、学習データを作るのは絶対に必要なことです。
大前:テストの段階で結果が出なかったら、即終了だと思って取り組んでいました。ここでいう結果とは、精度が悪いということです。最初なので、データ数も2000~3000個ほどありましたが、そこである程度の精度が出ればゴールで、高精度なものが出なければ終了しようと。システムが完成していれば、すぐにテストはできるのですが、英語版しかないBERTをシステム上で動くようにするのに苦労しましたね。
――北島さんが発案し、大前さんがAIの学習モデルを作りました、と。今度はその辺りから、インフラ部分を担う髙橋さんがご登場されるのですね。
髙橋:そうですね。僕は大前さんが作っているAIが稼働する環境と社内のファイルサーバがファイルのやり取りをする部分、ファイルの転送や結果を返したりするシステム連携を担当しました。主に環境整備が僕の役目でしたね。データは会社のシステム内にあるので、そことマッチさせて審査をする必要があるので、その間を繋ぐ役目というイメージです。

技術的な難しさよりも、会社が大きすぎるせいで、関連部署がたくさんあるという点に難しさを感じました。例えばファイルサーバを管理している部署もあれば、AIを走らせることができる解析環境を持っている部署もある。とはいえ、AIを実際に作っているのは我々なので、業務領域がいくつかの部署にまたがっていました。
今でこそクラウド化が進んでいますが、実際に中身を見ると、まだまだサーバがいくつか残されていて、そのサーバを管轄している部署もすべて違います。前職の会社は50人規模だったので、例えばバグが出ていても、どこを見ればいいのかはすぐにわかったのですが、弊社の場合、範囲は広く、部署ごとに分断されているので、連携して他の部署にお願いしたり、問題が起きても何が問題なのか、その情報をどこからどう得れば良いのかというところからのスタートとなりました。なぜ上手くいかなかったのか?ということすらも、誰かに聞かなければ分からないといった状況でしたね。しかもサーバを管理している人でなければ中身が見れない状態になっていて、置いてあるファイルに対して書き込みも読み込みも出来ません。
――部署が複数にまたがるので、開発者としては何か起きたときにどの部署で何を管理しているのかを知っていないといけないということですね。
北島:そうなんです。部門ごとにサーバがあるんですが、そこに審査対象となる求人票の案件ナンバーのリストがあるので、まずそれを取得します。そこに求人票の情報がひもづかないとシステムを回せないのですが、肝心の求人票情報は分析環境の中にあります。その分析環境にある情報と求人票の案件ナンバーと合わせる必要があるということですね。少し流れを説明しますね。
まず、ファイルサーバに審査部門の人が、審査したい対象のエクセルファイルを起きます。(矢印①)そこには案件ナンバーが書いてあるので、分析環境内のAというサーバへ自動で置かれます。AWSサーバ側にいわゆる“BERT求人審査モデル”があり、そこに渡す前に情報を加える必要があるので、分析環境のBというサーバから求人票の職種名と仕事内容を持ってきて合わせます。(矢印②)その上で求人審査モデルをまわして、仕事名称、依頼内容に優位性表現の抽出結果を加えます。(矢印③)
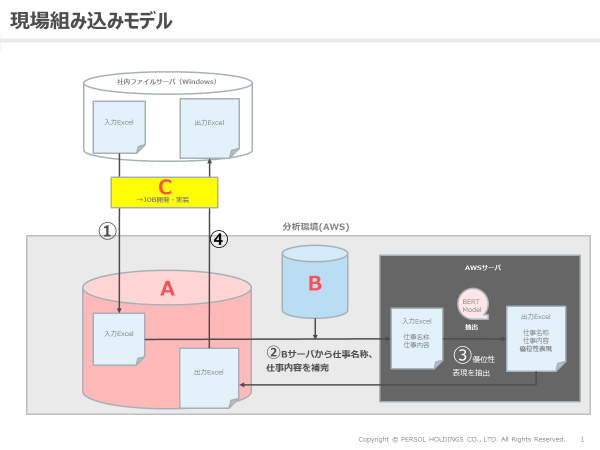
髙橋:ファイルサーバ自体は1つで、分析環境はAWSです。北島さんが先ほど説明してくれたAサーバで連携するのですが、Aサーバにアクセスできて、かつファイルサーバにもアクセスできる“何か”が必要になります。要するに自動で走らせるためには、何かしらファイルサーバをマウントできて、なおかつAサーバにアクセスできるネットワークがあいたサーバがどこかに必要になるということですね。
しかし、それを持っているのは我々ではなくBITA統括部です。なので今回の場合、我々が動かしたいプログラムはBITAに乗せてほしいと依頼して、ファイルを置くところはホールディングス管轄のグループITに依頼する必要がありました。ファイルの置き場所が物理的に違うこともありますし、管轄している部署も違います。物理的な分離と組織的な分離の2種類があったので、その調整が必要でした。
――調整前に入る前に、髙橋さんが現状を見たということですよね。まず全体像を把握してから、必要各所に話を持っていったというイメージでしょうか。
髙橋:いえいえ、割と行き当たりばったりでしたね。全体像を見たくても、この会社の全体像を把握するのは非常に難しいんですよ。Aサーバとファイルサーバを繋ぐことを最終形として、そこから逆算して、まず何が必要なのかを考えていきました。最初は別の方法にチャレンジしていたんですが、どうにも無理だという事が分かったので、次に他部署で同じようなことをやっていないかと思い、BITAに相談をしました。BITAでは異なる使い方をしていたこともあって、開発手法もかなり我々と違っていたので、少し戸惑いましたが、これまでの経験からも「どこかで何とかなるだろう」とも思っていましたね(笑)
大前:いわゆる“求人審査モデル”を作ってからのシステム化については、北島さんと髙橋さんにバトンタッチした形になってしまっていたので、僕はその点に関して、あまり苦労はしていませんでしたね。もっとも大変だったのはやはり、求人審査モデルを作るまでの過程ですね。初めて日本語で検証をしたり、モデルを作っているサーバがうまく動かないといったこともありました。いちばん困ったことは、新型コロナウイルスの影響で出社ができず、分析環境にアクセス出来なかったことですね。この4月は本当に何もできませんでしたね。
「三位一体」となったプロジェクトの進め方
――それぞれ立場が違う3人がいったいどのように連携しているのか。その様子を教えていただけますか。
大前:システムに乗せるときは絶対に3人で連携します。僕はモデルを組み込んで動かすところを作ったり、例えばファイル転送や案件抽出をし、優位性表記を抽出するところは私が担当しました。僕は自分のところで閉じているので、他部署と調整が発生しなかったことはラッキーでした。調整はお2人にやっていただきましたので、ご苦労はおかけしてしまいましたが…。

北島:私は、申請関係を一手に引き受けました。システムを構築するだけでなく、データを取り出さなければならないので、分析環境の中の「どこで、誰が、何をしているのか」を管理する情報セキュリティ部門への申請が必要になります。
今回は手続きも特殊でした。通常の分析環境の申請は、何らかのデータを分析環境から出し入れをするというものですが、今回は分析環境にデータを入れて、モデルを回した結果をアウトプットするというもの。データを入れるときと、データを出すときと、合わせて二度の申請が必要でした。また、どのようなデータを出すのかも再度ヒアリングさせてほしいと情報セキュリティ部門から申し入れがあり、私の方でその調整もしましたね。
――システムを中心にして、それぞれが役割を認識して動いていたんですね。現状のステータスとこれからを教えてください。
北島:7月の頭あたりから運用しています。求人審査モデルで抽出した結果を審査部門に返していますが、まだ第一段階で、ただ抽出しているだけの状態で、それがNGなのかどうかという判定までは実施していません。今はまだ優位性表現である可能性を抽出して教えている、という段階ですね。
今後は、優位性表現を見つけた場合、それが本当に優位性表現なのかどうかを確認します。優位性表現の根拠が書いてあればOKなのですが、根拠が書いて無ければNGとなります。例えば「業界ナンバーワン」と書かれていても、その前後に業界ナンバーワンの根拠が示されていればOKということですね。今できているのは、その優位性表現を見つけるところまでで、その根拠の有無の判定ができるまでは至っていません。今後はそこにも挑戦していきたいと考えています。
――根拠の抽出まで…!審査部門での業務にも変革がありそうですね。皆さんがこのプロジェクトに関わる中でのスタンスや心持ちを教えてください。
大前:アナリティクス的なことではありませんが、とにかく一日でも早くリリースしたいと考えていましたね。モデルについて話をしていたのは3月で、3人で開発を始めたのは4月。審査部の人たちにもかかわってくることなので、本当は4月中にリリースしたいくらいの勢いでした。
チーム的には北島さんも髙橋さんも優秀なので、こちらから何かを依頼するとほとんど引き受けてくれました。おかげさまで僕は抽出精度にだけ集中することができました。周囲にプロフェッショナルがいるので、そこはお任せをして、自分のことに集中した方が早くリリースできると思いましたね。
髙橋:僕も同じように、モデルの精度は大前さんにお願いし、それを繋ぎこむところは僕が受け持つという心持ちでいました。申請は北島さんに投げましたが、結果的に北島さんがいちばん面倒なところを担うことになってしまいましたね(笑)。

――なるほど。では北島さんは、エンジニアがスピーディにモノ作りに取り組める環境づくりを意識していたということですかね。
北島:そうですね。大前さんも髙橋さんもプロフェッショナルなので、僕が出来ないモデル作りや環境作りに集中して気持ち良くやっていただくために、それ以外は僕がやろうと思っていました。また、ビジネス担当の役割としては、成果を出さなければならないので、今回、抽出した結果をどのように使うか、そこからどのようにして横に広げていくかを考えることが必要で、今まさに現場とのすり合わせをしています。
このチームだからこそ生み出せる価値があるーー
――ひと区切りついた段階で感じられた、このプロジェクトのやりがいや醍醐味を教えてください。
北島:僕はもともとビジネスを作りたいと思ってこの会社に入社しているので、今回のプロジェクトを通じて、最終的にはビジネスにつなげることを考えています。今回のように何かしらリソースが割かれている部分に対して、自分たちのテクノロジーを活用して、外部に向けて展開することでビジネスになると思うので、今はそのモチベーションで動いていますね。

髙橋:想定していた以上に、多くの壁はありましたが、ひとつ言えることは、それが良いか悪いかは別として、多方面の経験を得ることができたと感じています。今回であれば、自分1人だったら絶対にやっていなかったであろう、従来ツールを使っての実装ですね。それが今後の役に立つかどうかは別として、経験の引き出しはひとつ増えたかとは思います。また、何をするにしても、他部署との連携は必要不可欠ですから、今後、様々な取り組みを進めていく上で、足掛かりになったとは思います。
この求人審査AIは、まだできたばかりのものなので、実際に連携には苦労しましたが、まだまだ始まったばかりの発展途上にある仕組みです。実際にGOサインが出て、本格化したら、いつまでも分析環境に乗せておくわけにはいかないので、今度はARCSなどの基幹システムとの連携が必要で、そこでもまた申請が必要で…と考えると、良くも悪くも、できることとやるべきことがたくさんあるので、経験はたくさん積めますね。
ただ、プログラミングだけをやっていたり、インフラ構築をするだけのエンジニアではなく、様々な回避手段を考えながら、単純にコードを書くだけではなく、限られた制約の中でスピード感を持って実装するための手段を考えることもセットで求められます。相当、やりがいはありますよ。
――今後、使わないかもしれない技術の経験にも価値があると思うのはなぜですか?
髙橋:本当に使わないこともありますが(笑)。例えば、世の中では今、pythonが流行っていますが、pythonだけでプログラミングをマスターし、エンジニアに転職しようということはできません。確かに言われた仕様通りに作るプログラマーにはなれるかもしれませんが、それはpythonに言われた仕様のプログラマーになれるだけです。
何が必要かというと、言語に依存しない考え方や設計思想を学ぶことです。それらは表面だけではなく、一見すると関係ないもののように見えても、アーキテクチャをひも解いていくと“そういう考え方・発想で動いているのか”という発見もあり、そこから繋がっていきます。反対に、言語に依存しない考え方や設計思想がしっかりとできあがっているエンジニアは、新しい言語が出てきてもわずか3日ほどで習得します。
これらはエンジニアに限らず、ビジネス全般にも言えるかもしれませんね。実際にやってみたうえで最終的に無駄だったという判断を下すことはあるけれども、その判断はきっと知識や経験を持っていないとできません。なので、そこに向かうまでに判断する材料として使う知識や経験は、今後何かの役に立つと思って価値があるというモチベーションでいますね。
――大前さんはいかがですか?
大前:このプロジェクトは求人審査AIプロジェクトとしても第一歩ですし、自然言語を使ったモデルとしても第一歩です。色々とチャレンジしてやっていきたい、ということがありまして、そうもしなければアナリティクスグループが必要かどうかという話になってしまいます。会社の上層部からも、失敗してもいいから数をこなしてほしい、AIを導入したプロジェクトをどんどん推進して数を打ってほしいと言われています。それができなければアナリティクスグループの存在意義が失われ、仕事も無くなってしまうので(笑)。実際のビジネスに活かしていく事例をどんどん作っていくことで、アナリティクスグループの価値を上げていきたいですね。
今回のように、BERTみたいな新しい技術を調査して研究しているだけでは意味がなくて、それをどうやって現場に組み込むかということが重要です。そこではじめて会社の利益に貢献できるのではないかと思いますね。

――アナリティクスの価値としても存在感は重要だと思いますが、大前さんの感覚として、アナリティクスを使ってビジネス解決できることはもっとたくさんあると思いますか。
大前:あると思います。しかし、この会社は開発期間が長いプロジェクトが多いので、もっと短期間で高速に開発したほうが我々もいろいろと試せると思うのですね。今回リリースの速度を意識していたのも、そういった理由からです。もし失敗しても、それを活かしてまた次に進めば良いのですが、開発にそもそも1年も2年もかかってしまうと、それも難しいですからね。
――今後、チャレンジしたいことがあったら教えてください。
大前:現在の求人審査AIは、まさにはじめの一歩。もっと精度を出して拡張をしていって、最終的にはARCSと連携するところまで持っていきたいと思っています。個人的には、今回のような案件をアナリティクスグループとして数多く取り組めるようにして、今年新卒で入社した2人にも経験をさせてあげたいと思いますね。新卒が配属されるということは、彼ら自身はもちろん、このチームも会社から期待されていることと思うので、どんどん仕事を増やしていければと思いますね。
髙橋:我々の部署はどちらかというと、多くの人員でひとつのプロダクトを作るというよりは、大前さんが言っていたようにサイクルを回す方が適しているので、どこまで作りこんでいくかという点も難しいところだと思っています。なので、もっとチームそのものを進化させていって、新しいものを次から次へと生み出していきたいですね。個人的には、最終的にはすべて経験として蓄積して、より部の底力を上げるため、最適なルートを見つけるための能力を得たいと思います。
――最後は、北島さんに締めていただきましょう。
北島:デジタルテクノロジー統括部で成果が出ているプロジェクトととして、このチームから生み出せたらいいな、と思っています。かなり良い形でアナリティクス・エンジニア・ビジネスが三位一体となり、それぞれの役割で価値を発揮できるような座組になっているので、ぜひ実現させたいですね。
そのために必要なことは、成果を出すというのは絶対ですが、この体制で新しいものを作っていけるのだという、ひとつの成功モデルになれたらと思います。ですから今回のように取材を受けてアピールするのもひとつの手ですし、色々とやっていきたいですね。
――先ほどお話しされたように、この会社の中にはビジネスにできそうなネタが他にもあるというイメージでしょうか。
北島:たくさんあると思います。もっとそういう観点で周囲を見渡していけば、まさに宝の山ですよ。個人的にはこのサービスを立ち上げて、サービスオーナーのようになれたら嬉しいですね。頼りになるプロフェッショナルがいるので、ご協力いただきながら実現していきたいですね。

――お互いが、役割を意識してプロジェクトを進めてこられた様子が伝わりました!ありがとうございました!
(取材・文=伊藤秋廣(エーアイプロダクション)/撮影=古宮こうき)

北島 寛康 Hiroyasu Kitajima
デジタルテクノロジー統括部 データ&テクノロジー ビジネス部 ビジネスグループ リードストラテジスト

大前 択悟 Takugo Omae
デジタルテクノロジー統括部 データ&テクノロジー ソリューション部 アナリティクスグループ シニアデータアナリスト

髙橋 大地 Daichi Takahashi
デジタルテクノロジー統括部 データ&テクノロジー ソリューション部 エンジニアリンググループ リードエンジニア
※2020年10月現在の情報です。