

皆さんはじめまして!今年4月にデジタルテクノロジー統括部へ新卒入社した長谷川智彦です。
デジタルテクノロジー統括部では昨年から新卒採用をスタートし、僕ともう1名の計2名が晴れて入社しました!
今回の企画はそんな僕らの学びの過程を外部に発信していこうと思っています。
長谷川智彦のプロフィール
大学時代の専攻は植物学・分子生物学。最近趣味でデザインをかじり出した社会人1年目。植物の実験データを正しく解釈するために統計を勉強し始め、データ分析に興味をもつ。データサイエンスはただいま必死に勉強中。
▼研修開始時点でのデータサイエンスの実力
内定をもらってから研究の合間時間で機械学習や統計の基礎知識を勉強していたレベル(はじパタや統計検定2級レベルの知識)。プログラミングはProgateでPython、SQL等の基礎文法を学んだ後、データサイエンティストになりたい人向けの本でNumpyやPandasの基本的な使い方や機械学習のライブラリの使い方を写経しながらやったことがある程度のレベル。ほぼ初心者です。
▼こんな方々におススメの記事にしたい!
- データサイエンス未経験の新卒を育成している方
- データサイエンスの経験問わず、パーソルキャリアでデータサイエンス周りの仕事に就きたいと考えている方
- デジタルテクノロジー統括部の取り組みを知りたい社内他部署のみなさま
デジタルテクノロジー統括部の新卒データサイエンティスト研修とはーーー
この記事では、僕たちが配属してから最初に出された研修課題の1つを紹介します。
期間はだいたい3週間。以下の課題に挑戦しました。
<課題>
Udemyで提供されている『【世界で18万人が受講】実践Python データサイエンス』とProgateのSQLのコースを行った後、KaggleのTitanicコンペに挑戦!
<目的>
構造化されているデータに対してPython ライブラリのNumpy, Pandas, Matplotlib などを使用した分析を行えるようになる。
他の研修課題もあったので意外と予定がパンパンになりましたが、研修内容を実際に行った感想などをこれから書いていきます!
Udemyなどのオンライン教材を使用してみて――
最近聞かないことがないくらいビックデータやAIが注目されています。データサイエンティストを目指す方やデータ分析に関して学んでみたい方向けのオンラインサービスも増えてきてます。デジタルテクノロジー統括部の研修ではその中でも様々な講座をオンライン動画で見れるUdemyからPython入門コースとプログラミング初心者の向けに実際にコードを記述しながらプログラミングを学べるProgate からSQLのコースを扱いました。
では実際にこれらのオンライン講座を僕がやってみた感想を伝えるとこんな感じです。
Udemy:自分で少しやっていたのでつまずかずことなく助かった!ただ、動画を見ながらコードを打つのは少しあわあわしながらになった。
Progate:スライドもついていてわかりやすい!何よりUIデザインがかわいい。
この感想を抱く理由を具体的に考えてみると、
1:Numpy、Pandas等のライブラリを触ったことがあったため、復習として行う感覚があり、改めてどんなことができるかを思い出しながらJupyter notebookにメモとして残していけたことが挙げられます。全くプログラミングに触れたことがなかった頃の自分では3週間の期間で理解できたとしても、実際に慣れて使えるようになるまでには短すぎたと感じます。
2:Progateはやったことがあったのですが、それでもレクチャーの初めにスライドで視覚的にわかりやすく説明してもらえながら進めていけるのでやりやすいと感じました。(特にターミナルやテキストエディターとは?となる方でも気兼ねなく始めれると思います。)
ひとまず、PythonとSQLの基本を学ぶためのオンライン講座の感想は復習するのにちょうどよかったという感じでした!(Pythonまだ触ったことないレベルの方だと3週間は習得にはかなり厳しいとも感じます。逆にインターンなどでデータ分析の経験がある方には物足りないと感じます。)
KaggleのTitanicコンペに挑戦!
一通りオンライン講座でPython基礎を学んだ後は、KaggleのTitanicコンペに挑戦しました。
<Kaggleとは?>
この記事はデータサイエンスに関して全く知らない方向けに作成しているので、「そもそもKaggleとは何ぞや?」といったところも説明させて頂きます。
Kaggleとは端的に言えばデータ分析力を競うコンペを開いているサービスです。企業や研究者が分析したいデータをプラットホームに投稿し、そのデータを世界中の統計やデータサイエンス等を勉強した方々が分析、予想モデルを組んで最適なモデルを競い合う場になります。
このコンペで上位に入るとメダルがもらえ、このメダルで実際にデータ分析力があるのかの指標にもなってきます。(いくつかの企業ではKaggleの結果を社内の評価にも反映しているそうです。)
研修では、Kaggleの数あるコンペの中から無期限で参加できるTitanicコンペに挑戦しました。(Kaggleに初挑戦する際によく練習に使用されるコンペです。)
このTitanicコンペは過去に沈没したTitanic号の乗客に関するデータを扱い、どんな乗客が生存したかを調べその予測モデルを作るものです。
<オンラインで挑戦!>
今回研修で扱ったUdemyの講座の中でこのTitanic号のデータを扱う講座があるので、初めは動画を見ながら挑戦しました。またその後、自分の視点での分析と予測モデルの構築にも挑戦してみます。
まずは、動画を見ながらでの分析を行い、Udemyの講座での分析結果の一部を紹介しますね。
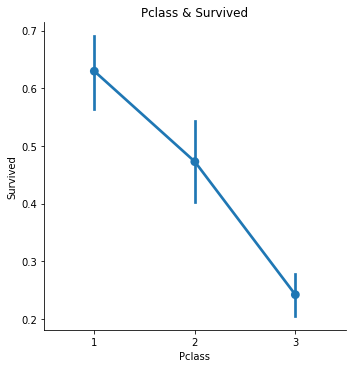
まず上側のグラフはチケットクラス(Pclass、1:上層クラス、2:中級クラス、3:下層クラスを表します)と生存率(Survived)の関係を表したグラフになります。
このグラフを見ると『チケットランクが下がると生存率も下がる傾向がある』ということがわかります。
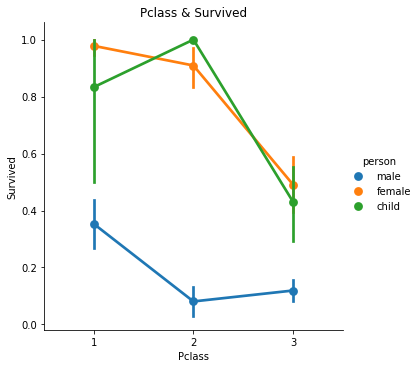
オンライン講座ではこの結果に加え、男性、女性、子供(15歳以下)ごとでのチケットランクと生存率の関係の分析を行い、その結果が下側のグラフです。
このグラフを見ると先ほどと同様にチケットランクが下がると生存率も下がる傾向があることはもちろんわかるのですが、この結果に加え、2つの新たな事実が見ていきます。
『男性の生存率が女性や子供と比較して低いこと』
『全体で見ると中級クラスの生存率は低いが性別ごとに分けてみると女性や子供の生存率は他のクラスと比較して高いこと』
このように視点を変えて分析を行うと、新たな情報が見えてくるのがデータ分析の面白い部分だと感じます(僕はこの面白さにはまりました)。さて、いよいよオンラインから自分たちで挑戦します!
・・・がここからは長くなるので次の記事で詳細にお伝えしますね。
次回の「データサイエンティストのたまご 育成日記」シリーズもお楽しみに!

長谷川 智彦 Tomohiko Hasegawa
デジタルテクノロジー統括部 データ&テクノロジー ソリューション部 アナリティクスグループ
※2020年6月現在の情報です。