

みなさん、こんにちは!デジタルテクノロジー統括部に新卒入社した長谷川智彦です。 データサイエンティスト未経験の新卒社員がデジタルテクノロジー統括部でどんなことをやっているのか、どのように成長していくのかの学びの過程を記録していくこの企画。今回は正規表現で勉強したことについて書いていきます。
今回実施したことと正規表現について
コンビニのおでんが食べたくなる季節になりました。今年もモチ巾着を食べようと思います。勝手に食べてくれって話ですね。さて、時はさかのぼり2,3か月前くらい前、ある案件でこのような依頼がありました。『求人原稿のテキストから欲しい情報を抽出して構造化データにできますか?』
つまり、文章から欲しい情報を抜いてきてほしいという依頼です。これを実現するために正規表現を使って抽出作業を現在も行っているのですが、今回その過程で勉強したことについてまとめていこうと思います!
この記事は一応データサイエンスになじみがない方にも読んでいただきたいので、どういった依頼かを簡単に説明させていただきます。私たちが提供している求人原稿には、企業情報や業務内容、想定年収、職種などさまざまな情報がテキストとして書かれています。求人原稿1つ見ても多くの情報があるのですが、これらの情報をテキストから抽出して、前回までの記事で見てきた構造化データ(数値や文字のデータを行と列の構造を持つテーブルに収めたデータ)の形に整えてほしいといった内容です。

しかし、テキストから欲しい情報を抜き出してくる際に課題になるのはテキスト内の表記にばらつきがあることです。例えば月給を例にとってみます。求人原稿をみると予定月給20万~30万円と記載されているものもあれば、月給20万5,000円~30万5000円と記載されているもの、月給二十万~三十万と漢字で記載されているものなどさまざまな表記をしているものが目につきます。また月給といっても20万~のものもあれば、30万~のものもあったりと月給の最低金額の範囲も異なります。これらのばらついた表現1つ1つを丁寧に抜き出すことは不可能ではないですが、とてつもない労力と時間がかかってしまいます。
そこで、今回は正規表現を使用して求人原稿から必要な情報を抽出することにしました。正規表現とは、複数の表記をまとめて認識できるように1つのパターンで表した表現のことです。
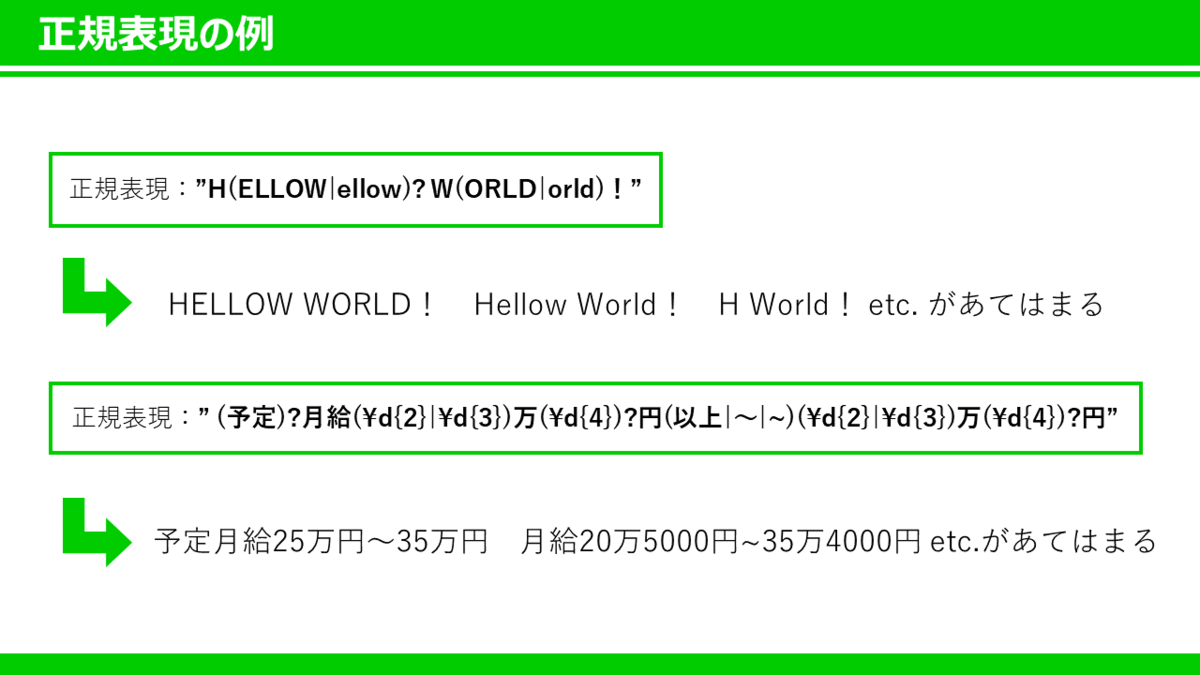
例えば”HELLOW WORLD!”と”Hellow World!”と”Hellow W!”という3つの表記が存在した時に正規表現では”H(ELLOW|ellow) W(ORLD|orld)?!”と正規表現では1パターンで表現します(Pythonでの記載例です)。上に挙げた月給の数字で記載されている例で行くと'(予定)?月給(\d{2}|\d{3})万(\d{4})?円(以上|~|~)(\d{2}|\d{3})万(\d{4})?円'と正規表現で記載することで予定月給20万~30万円と月給20万5,000円~30万5000円をテキストから抽出することができます。後は抽出した値をまとめてデータフレームにすると構造化データが作れます。
メタ文字について
ここで、いきなり\d{}や(|)、?などを出しましたがこれは正規表現でメタ文字と呼ばれるもので、この特殊文字が持つ条件を使って正規表現を作成していきます。以下に代表的なものを示します。
(さらっと書きましたが有名なもの以外は僕もまだうろ覚えなので実際にパターンを作る際は何度もネットで見直しています。初めは*と?を逆に覚えていたり、半角と全角は別で作成しないといけないことを知らずにあれ?抜けないぞ?ということを何度も行っていました。)
先ほど挙げた月給の例'(予定)?月給(\d{2}|\d{3})万(\d{4})?円(以上|~|~)(\d{2}|\d{3})万(\d{4})?円'でいくと
(予定)?:単語「予定」が0 or 1回現れる
(\d{2}|\d{3}):2桁の数字 or 3桁の数字(\dが数字を表します)
(\d{4})?:4桁の数字が0 or 1回現れる
(以上|~|~):以上or「~」or「~」のいずれか
なので予定月給20万~30万円(予定が1回現れる+月給+数字2桁+万+「~」+数字2桁+万円)でルールを満たしており認識されます。月給20万5,000円~30万5000円においても(予定が0回現れる+月給+数字2桁+万+数字4桁+「~」+数字2桁+数字4桁+万円)でルールを満たすので認識されます。こういったルールを複数作成し、テキストから欲しい情報を抜き出して構造化データにまとめ、前処理を行えば、晴れてデータ分析に直接利用できます(ただ、実際は正規表現に全然慣れていなかったのでパターンを作成しては抽出できるか試すを試していました。途中から簡単に正規表現が正しいか確認してくれるツールがあることを知ったのでそれを使って最近は確かめています)。
reモジュールについて
今回分析にはPythonに標準ライブラリとして存在するreモジュールを使用しました。その中でも便利だった関数の一部と1つだけコードを書いておきます(例として載せているコードなので実際に活用する際はネットにある詳しいコードを参照ください。個人的には抜き出した値をgroup()で抜き出せることに気づくのに少し時間を使ってしまいました。また、正規表現のパターンがあっているのにテキストにないとエラーが出る場合はr’正規表現パターン’のように先頭にrを付けると指示が通ることがありました)。
## 正規表現での記述のモデルコード例 text = '2022年 パーソルキャリアへようこそ! あなたの活躍を期待しています。' ## reモジュールのインポート import re ## 正規表現を交えて抜き出したいパターンを記述 pattern = r'\d{4}年 (パーソルキャリア|PCA)へようこそ!' ## 関数で抽出 result = re.search(pattern,text) ex = result.group() print(ex) ##結果 2022年 パーソルキャリアへようこそ!
総括
今回は正規表現に関して簡単に書きました。今回を通じてこんなことを学びました…!- 正規表現を複数作成し、ルールベースで抽出したり存在の有無のフラグを立てて構造化データを作成できることを知った。
- 表記のばらつきが思っていたよりも多く、正規表現の作成に頭を使った。
- macth関数は知っていたがそれ以外にも色々な関数があり、出来ることの引き出しが増えた。
- パターン1つにつき1つのfor文を書いていたが非効率∧時間がかかってしまうことを実感し、リストにして2重のfor文にすることで楽することを覚えた。
次回は関わっているプロジェクトで使われているモデルや分析手法で学んだことに関して書いていこうと思います。それでは次回もデータサイエンティストのたまご育成日記をお楽しみに!

長谷川 智彦 Tomohiko Hasegawa
デジタルテクノロジー統括部 データ&テクノロジー ソリューション部 アナリティクスグループ
大学時代の専攻は植物学・分子生物学。最近趣味でデザインをかじり出した社会人1年目。植物の実験データを正しく解釈するために統計を勉強し始め、データ分析に興味をもつ。データサイエンスはただいま必死に勉強中。
※2020年12月現在の情報です。