

こんにちは。デジタルテクノロジー統括部に新卒入社した長谷川智彦です。
データサイエンティスト未経験の新卒社員がデジタルテクノロジー統括部でどんなことをやっているのか、どのように成長していくのかの学びの過程を記録していくこの企画。今回は回帰モデルのデータ分析の研修について書いていきます!
新たなデータ分析研修ー回帰編ー
コロナで引き続き自宅で研修を行なっているのですが6月から新たな研修課題に取り組んでいます。\\ KaggleのHouse Pricesデータを使用して回帰モデルの分析をやってみよう!//
「Kagggleでの分析は前回の記事でやってなかったっけ?」と思われた方、前回の記事も読んでくださってありがとうございます!前回と似たような研修だと感じる方もいらっしゃるとは思いますが、前回と違うポイントは今回は分類ではなく回帰問題を分析したところです。
回帰ってなんだ?
回帰ってなんだ?と思われた方、目の付け所が素晴らしいです。機械学習における教師あり学習には大きく2タイプ、分類と回帰があります。分類は前回の Titanic号の生死予測のようにいろんなデータを入れて得る予測値がどこのクラスになるかを予測するモデルのことをいい、回帰はデータから連続した数値を予測するモデルのことを表します。簡単な例を挙げるなら、動物関連の情報データを与えてそれがイヌなのかネコなのかを予測するのが分類、環境や繁殖などのデータも与えて犬や猫の個体数を予測するのが回帰と言った感じです。(例えがわかりにくかったら申し訳ないです。)

今回の研修ではKaggleにある「House Prices: Advanced Regression Techniques」コンペのデータを使用して様々な変数から住宅の売値を予測することに挑戦しました!
データクリーニングの地道な道のり
それでは、機械学習のモデルを組む前にどんなデータがデータセットにあるのか調べてみました。それが以下の表になります!
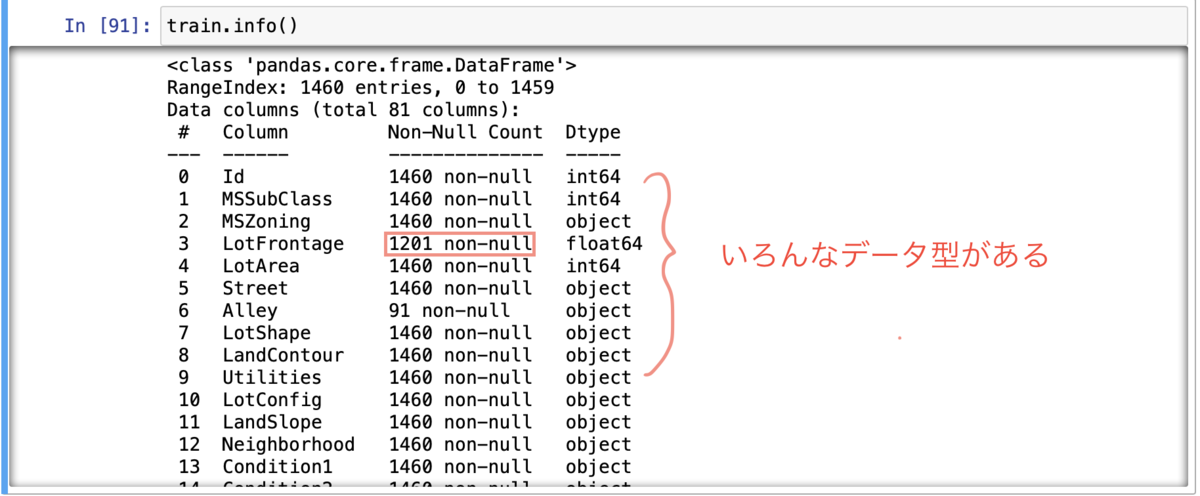
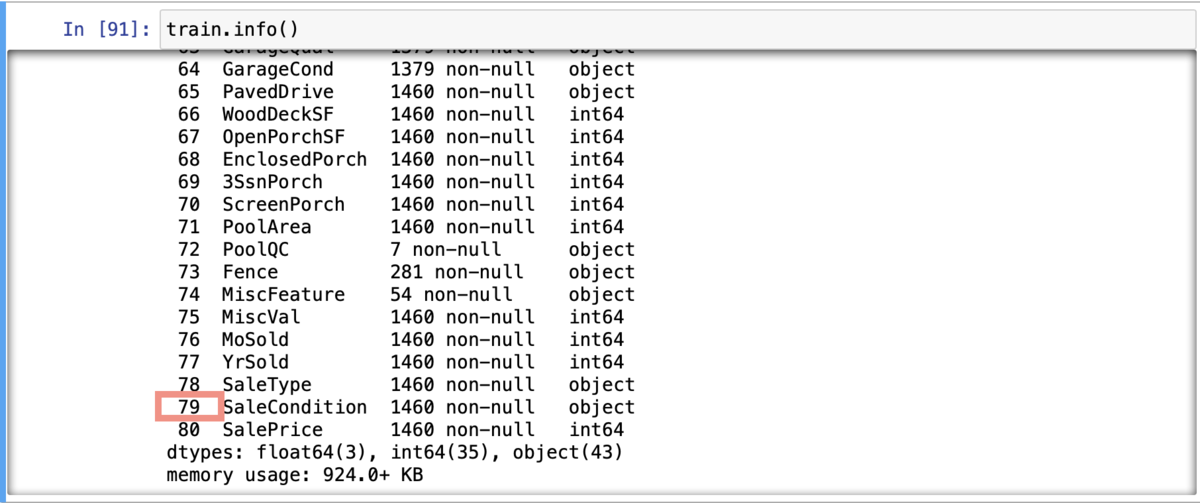
わー、変数が80個もある、しかもデータも欠損していてデータ型もバラバラだぁ〜、、、。どうやら今回もデータのクリーニングが必要そうです。一応、散布図とヒストグラムをざっくりと作ってみると、
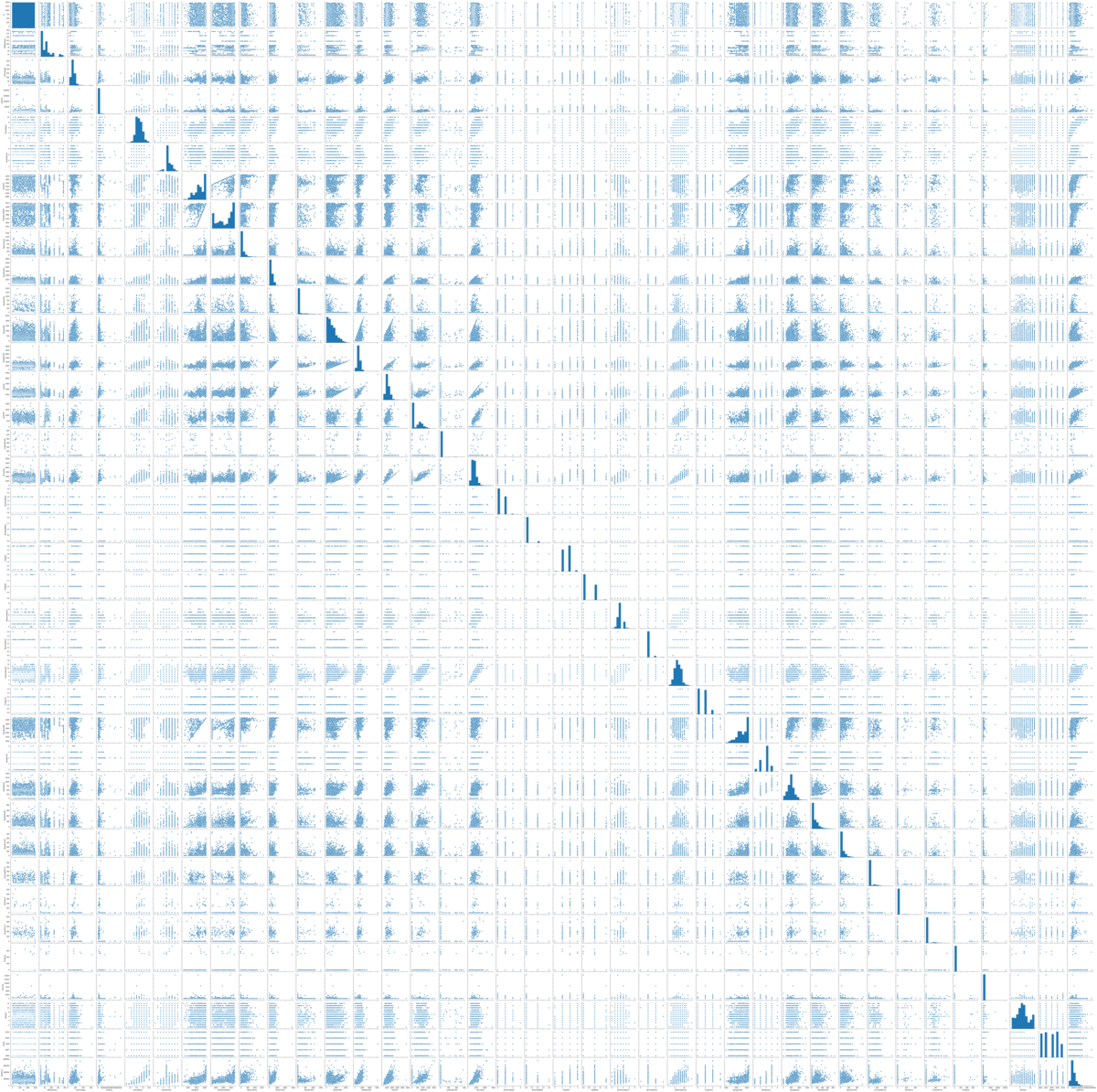
いっぱいありますね、、、。こういうのは目安をつけて絞った方がいいなと感じました。なんとなく、相関がある変数もありそうだなと感じたのでそこは意識しながらクリーニングしていこうと思います。
さて、データを整えなきゃと考え、まずは非数値データを数値データに変換しようと考えた僕は前回覚えたてのLabelEncoder()を使おうと思い立ち何も考えずに試しました。
import sklearn.preprocessing from sklearn.preprocessing import LabelEncoder le = LabelEncoder() for column in ["ExterQual","ExterCond","Foundation","BsmtQual","BsmtCond","BsmtExposure","BsmtFinType1","BsmtFinType2","Heating","HeatingQC","CentralAir","Electrical","KitchenQual","Functional","FireplaceQu","GarageType","GarageFinish","GarageQual","GarageCond","PavedDrive","PoolQC","Fence","MiscFeature","SaleType"," SaleCondition"]: le.fit(train[column]) train[column] = le.transform(train[column]) le.fit(test[column]) test[column] = le.transform(test[column]) train.head()
結果は、

見事にエラーコードを叩き出しました。エラーコードの指示も意識しつつ、ネットで原因を探すとLabelEncoder()はNaNがあるとエラーが出るとのことでした。なので再度データの情報を見直してみると
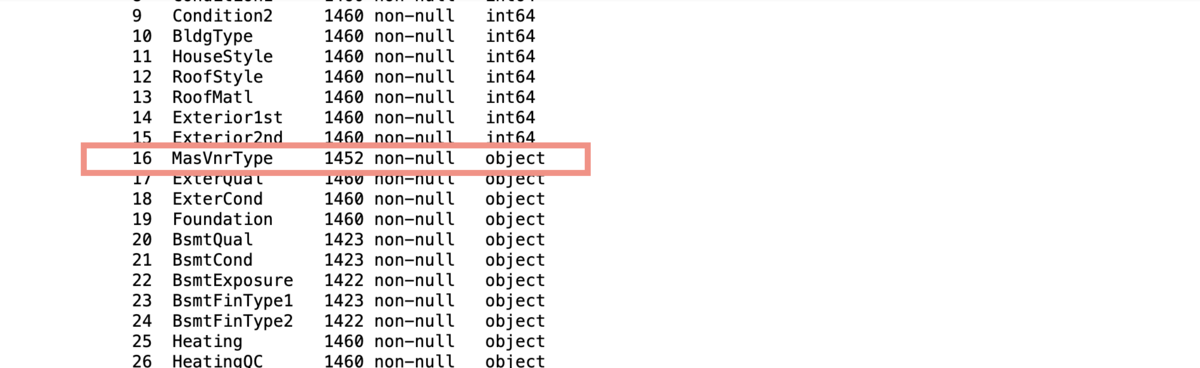
確かにデータが欠損しているカラムがありました。本来はまずデータが欠損してないかを確かめるべきでした。ちょうどこの頃、自習でデータの欠損を勉強し始めたのでまずはvalue_counts()とisnull()でデータの状態を確かめました。
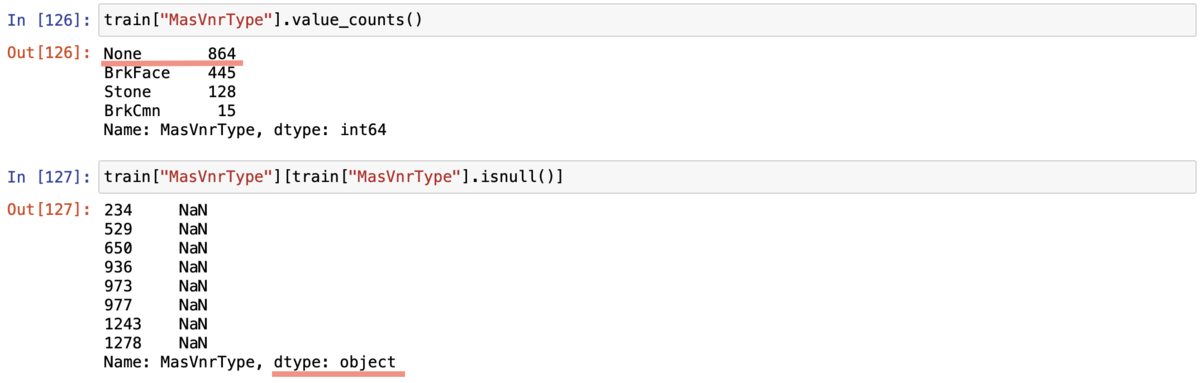
すると2つのことがわかりました。(赤線を引いた部分です。)1つはNaN以外でデータがないところにNoneが入っていること。2つ目はNaNがstring型で入っていました。何がまずいかというと、欠損値を埋めてくれるfillna()という関数があるのですがこれはNoneや文字列として入っている”NaN”があるとうまく対応してくれません。なので一旦これらをNumpyライブラリのnp.nanで置き換える必要があります。ということでfillna()を含め、一連の作業を行いました。(以下は置き換えとfillna()で値を埋めた簡易例です)
train["MasVnrType"] = train["MasVnrType"].replace("NaN",np.nan).fillna("-") train["MasVnrType"] =train["MasVnrType"].replace("None",np.nan)
この後同様にLabelEncoder()で処理を行い以下の表を最終的に得るまで至りました。
LabelEncoder()前

LabelEncoder()後

さて、ここまできたときに僕はしまったと思ってしまいました。それは、質的データをOneHot表現にしないといけない、というものです。
例えば(赤,青,緑)というデータがあったとすると、現時点で質的データは(赤:1,青:2,緑:3)などのように数字でラベル付けが行われています。しかし、この数字をそのままモデルに入れてしまうと、数字の大きさが結果に影響を与えてしまいます。この例だと、緑の方が赤よりも3倍大きい値として計算されてしまうことになります。しかし、このラベルはデータ同士を区別するために便宜上つけたものであって、値の大きさに意味を持たせたくはありません。そこで、学習の際は変数として単にその値であるか否かを分けるように0と1のラベルを与えます。
| id | 色 | ラベル |
|---|---|---|
| 0 | 赤 | 1 |
| 1 | 青 | 2 |
| 2 | 緑 | 3 |
↑色をLabelEncoder()で表した場合
| id | 色 | 赤 | 青 | 緑 |
|---|---|---|---|---|
| 0 | 赤 | 1 | 0 | 0 |
| 1 | 青 | 0 | 1 | 0 |
| 2 | 緑 | 0 | 0 | 1 |
↑色をOneHot表現で表した場合
このようにラベル付けすることで、青が赤の2倍であるとか、緑が赤より2大きいというような事態を避け、(赤,青,緑)の違いを平等に表現できます。
こういった0と1を使用したラベリングの表現をOneHot表現と言います。
ということで改めて欠損値の処理を行い、get_dummies()によってOneHot表現に変えました。
train_dummy = pd.read_csv("train2.csv") train_dummy = train_dummy.replace("NaN",np.nan) train_dummy = train_dummy.replace("None",np.nan) train_dummy = train_dummy.fillna("a") train_dummy = pd.get_dummies(train_dummy)
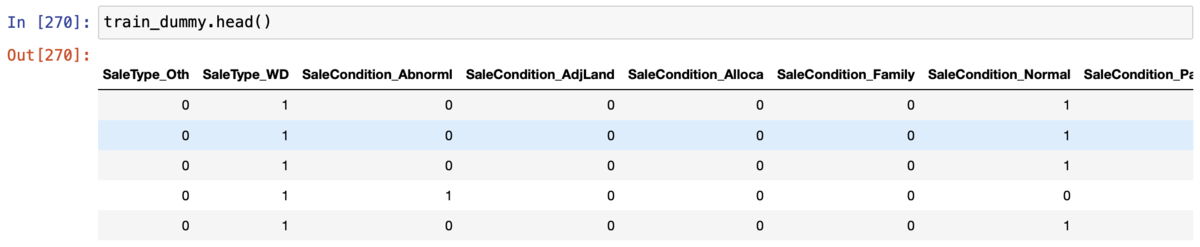
質的変数のカラムも0と1の値でOneHot表現になっていそうです。
それではこれからはりきってモデルの構築に移っていこうと思いますが、前回の分類予測と同様に、モデルの構築まで書いてしまうと長くなってしまうので今回はここまでにします。次回の記事でモデルの構築と評価を行っていくので是非お楽しみにしていてください!

長谷川 智彦 Tomohiko Hasegawa
デジタルテクノロジー統括部 データ&テクノロジー ソリューション部 アナリティクスグループ
大学時代の専攻は植物学・分子生物学。最近趣味でデザインをかじり出した社会人1年目。植物の実験データを正しく解釈するために統計を勉強し始め、データ分析に興味をもつ。データサイエンスはただいま必死に勉強中。
※2020年8月現在の情報です。